データベースライブラリTkrzwのバージョンを1.0にした機会に、改めてベンチマークテストをしてみた。最も典型的なデータベースクラスであるファイルハッシュデータベースにて、1億レコードのSetで200万QPS以上、同じく1億レコードのGetで500万QPS以上のスループットが出ることが確かめられた。
バージョン番号なんてのは所詮はconfigureの変数の値に過ぎないので、1.0にしたからって、それで性能や品質が向上するわけではない。20世紀までは、1.0未満はベータ版的な認識をする風潮があったが、継続的な更新が常識となった昨今では、そんな区切りに意味はない。とはいえ、私個人としては、バージョン1.0までは積極的に機能追加を行い、一通りやりたいことが終わったら1.0にするという目論見があった。さて、TkrzwのTODOリストがついに空になったので、最新バージョンの0.9.53を1.0ということにしよう。以後も開発は続けるが、とりあえず一区切りということで。
公式ページに載せている性能評価は0.5.30のものだったが、そこからそれなりの最適化をして性能向上しているので、ここで改めて評価をし直そう。Tkrzwの以下のデータベースクラスを評価対象とする。
- HashDBM : ファイルのハッシュ表のデータベース。
- TreeDBM : ファイルのB+木のデータベース。
- SkipDBM : ファイルのスキップリストのデータベース。
- TinyDBM : オンメモリのハッシュ表のデータベース。
- BabyDBM : オンメモリのB+木のデータベース。
- CacheDBM : オンメモリのLRU自動削除機能付きハッシュ表のデータベース。
- StdHashDBM : オンメモリのstd::unorderd_mapのスレッドセーフなラッパー。
- StdTreeDBM : オンメモリのstd::mapのスレッドセーフなラッパー。
実行環境のOSは、Linux 5.8(Ubuntu 20.04)で、CPUは6コア搭載3.5GHzのIntel Xeonで、メモリは32GBで、ファイルシステムはEXT4で、ストレージはSATA接続で読み込み速度402MB毎秒のハードディスクだ。実際に実行したコマンドなどの詳細は、Tkrzwの本家ページの性能評価の項目をご覧いただきたい。
100万レコードのシーケンシャルアクセスの性能評価をする。キーを"000000000"、"000000001"、"000000002"と変化させるので、B+木やスキップリストではシーケンシャル(順番通り)なアクセスになる。もっとも、ハッシュ表のデータベースには順序という概念がないので、シーケンシャルかどうかはどうでもよいのだが。いずれにせよ、SetとGetとRemoveを各100万回実行し、各々の秒間スループット(QPS)と最大メモリ使用量(MB)とファイルサイズ(MB)を測定する。
| Set | Get | Remove | Memory Usage | File Size | |
| HashDBM | 1,600,530 | 1,912,690 | 1,333,314 | 29.1 | 26.8 |
| TreeDBM | 1,688,254 | 1,795,384 | 1,575,017 | 68.2 | 17.8 |
| SkipDBM | 1,170,239 | 440,449 | 1,231,297 | 78.3 | 19.3 |
| TinyDBM | 2,755,223 | 3,211,469 | 3,133,763 | 52.8 | - |
| BabyDBM | 2,294,810 | 2,470,148 | 2,162,560 | 63.5 | - |
| CacheDBM | 2,702,272 | 3,451,943 | 3,144,269 | 71.3 | - |
| StdHashDBM | 1,744,610 | 2,715,155 | 2,630,603 | 99.9 | - |
| StdTreeDBM | 1,408,435 | 3,171,753 | 3,109,974 | 107.0 | - |
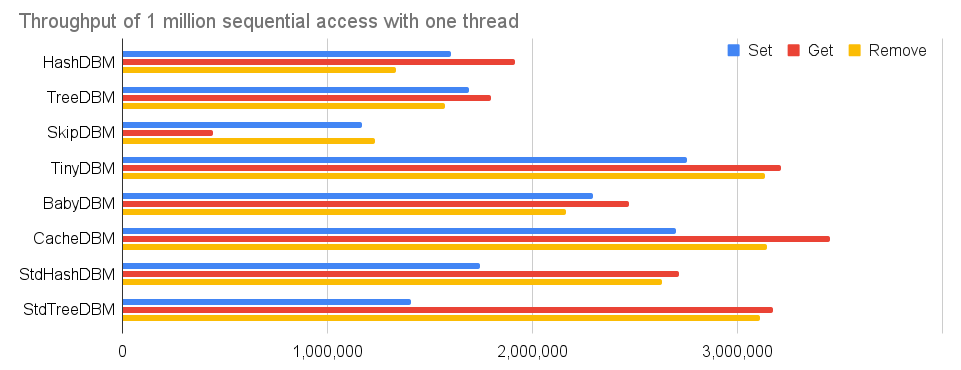
100万レコードという小規模なのもあり、各実装とも非常に高いスループットを叩き出している。HashDBMが各種オンメモリデータベースの半分以上のスループットを出せていることが素晴らしい。また、このシーケンシャルアクセスという好条件ではTreeDBMの性能がHashDBMに匹敵する。
上述の100万レコードのテストを、10スレッドで並列して実行した場合の性能表をする。つまり、各スレッドが10万回のSetやGetやRemoveを行う。
| Set | Get | Remove | RAM Size | File Size | |
| HashDBM | 2,015,638 | 4,247,388 | 2,549,070 | 29.1 | 26.8 |
| TreeDBM | 1,766,662 | 3,960,807 | 1,810,971 | 79 | 19 |
| SkipDBM | 876,747 | 1,851,018 | 979,760 | 86.8 | 19.3 |
| TinyDBM | 5,933,872 | 9,683,170 | 8,819,345 | 55.5 | - |
| BabyDBM | 3,096,330 | 10,605,335 | 3,436,732 | 51.4 | - |
| CacheDBM | 8,014,691 | 11,169,442 | 11,270,406 | 72.0 | - |
| StdHashDBM | 1,144,803 | 14,316,594 | 1,710,431 | 100.0 | - |
| StdTreeDBM | 1,124,624 | 14,376,462 | 2,130,565 | 107.2 | - |
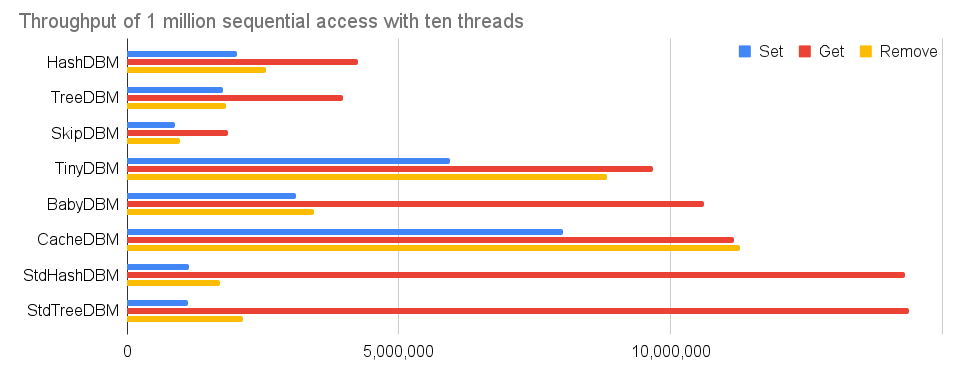
10スレッドで並列実行しているのだから10倍早くなってほしいところだが、現実はそんなに甘くはない。とはいえ、単純にデータベース全体をロックする実装ではむしろ遅くなるはずのところ、きちんと性能向上を果たしている実装が多い。HashDBMでSetが200万QPS、Getが400万QPSを出せるのは素晴らしい。SkipDBMで更新系のスループットが上げられないのは設計上の制約だ。
100万レコードでは規模が小さすぎるし、シーケンシャルアクセスでは効率よく処理できすぎる実装があるので、もう少し意地悪というか、現実に即したテスト条件にしてみる。1億レコードのランダムアクセスだ。すなわち、"00000000" から "99999999" までの10進数値の文字列をランダムに選択して、GetとSetとRemoveを1億回ずつ行う。
| Set | Get | Remove | RAM Size | File Size | |
| HashDBM | 1,229,364 | 1,640,083 | 1,431,386 | 1788.1 | 1828.2 |
| TreeDBM | 187,438 | 134,910 | 328,501 | 3663.1 | 1714.3 |
| SkipDBM | 440,309 | 210,564 | 441,649 | 3036.7 | 1225.7 |
| TinyDBM | 2,335,055 | 2,511,775 | 2,813,868 | 3573.5 | - |
| BabyDBM | 498,647 | 493,190 | 498,655 | 2951.4 | - |
| CacheDBM | 2,185,080 | 2,206,859 | 2,779,037 | 4753.8 | - |
| StdHashDBM | 1,802,910 | 2,242,933 | 2,598,990 | 6410.1 | - |
| StdTreeDBM | 474,017 | 519,097 | 518,196 | 6596.3 | - |
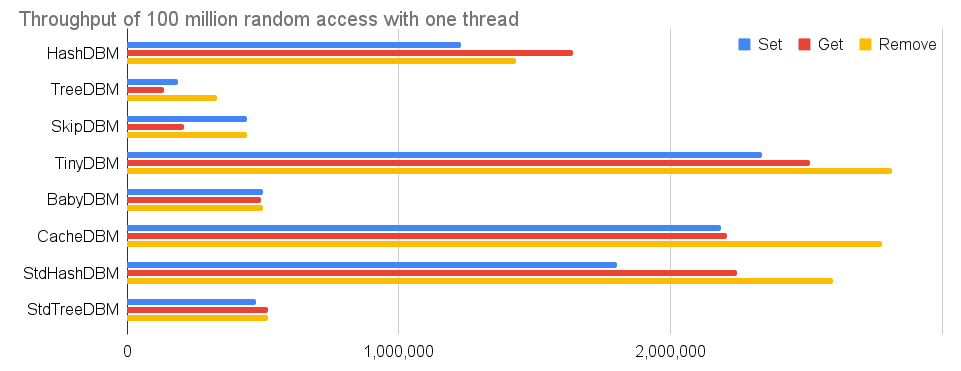
クエリの多くがキャッシュ上のデータだけでは処理されないようにテスト環境を設定したので、どの実装でも小規模のテストケースに比べるとスループットが落ちている。さらに、TreeDBMとSkipDBMは、ランダムアクセスになった分だけデータベース内のキャッシュが効きづらくなって苦戦している。しかし、現実のユースケースではアクセスパターンがシーケンシャルなキーの連続であることは期待できないので、このテスト結果が本来の性能に近いと言えるだろう。
上述の1億レコードのテストを、10スレッドで並列して実行した場合の性能表をする。つまり、各スレッドが1000万回のSetやGetやRemoveを行う。マルチスレッドでスループットを追求するユースケースでの性能指標としてこの結果はふさわしいはずだ。
| Set | Get | Remove | RAM Size | File Size | |
| HashDBM | 2,259,227 | 5,327,723 | 3,803,961 | 1788.3 | 1828.2 |
| TreeDBM | 343,564 | 509,779 | 536,877 | 5520.8 | 1722.2 |
| SkipDBM | 393,086 | 1,381,291 | 418,209 | 3036.8 | 1225.7 |
| TinyDBM | 8,246,833 | 9,151,282 | 9,272,530 | 3573.4 | - |
| BabyDBM | 1,239,584 | 3,754,941 | 1,187,900 | 2970.9 | - |
| CacheDBM | 9,314,902 | 9,711,285 | 11,446,497 | 4754.0 | - |
| StdHashDBM | 1,279,515 | 13,572,641 | 1,794,882 | 6410.1 | - |
| StdTreeDBM | 374,263 | 4,118,937 | 407,559 | 6596.1 | - |
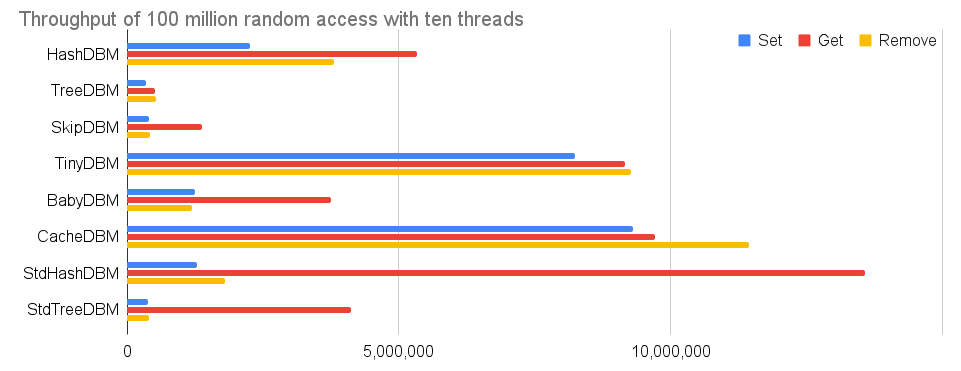
オンライン系のユースケースで、データベースを抱えたサービスがどれだけのスループットを出せるか見積もるのに適した条件を設定したつもりだ。HashDBMもTreeDBMもマルチスレッドの恩恵がきちんと出ている。HashDBMはこの規模でも200万QPSでSetしたり500万QPSでGetしたりできる。時間計算量O(1)であるハッシュ表を使うHashDBMの威力がここに光る。オンメモリだが同じくハッシュ表を使うTinyDBM、CacheDBM、StdHashDBMも、非常に高い性能を示している。
このテストのようにキャッシュが非常に聞きにくいアクセスパターンだと、ツリー系のデータベースの性能は著しく落ちてしまう。それでも、TreeDBMは30万QPSでSetしたり50万QPSでGetしたりできる。SkipDBMは130万QPSでGetできる。
SkipDBMとStdHashDBMやStdTrerDBMの更新系の性能が伸びないのは、全体(=テーブルロック)の共有ロックで排他制御を行っているからである。その他の実装ではより細かい粒度のロックを行っているので、スレッド数を増やすと性能がそれなりに向上する。大規模なユースケースでの実際の並列性はストレージデバイスの並列処理性能に律速されるので、高性能なSSDを使うとより良い結果が得られるだろう。
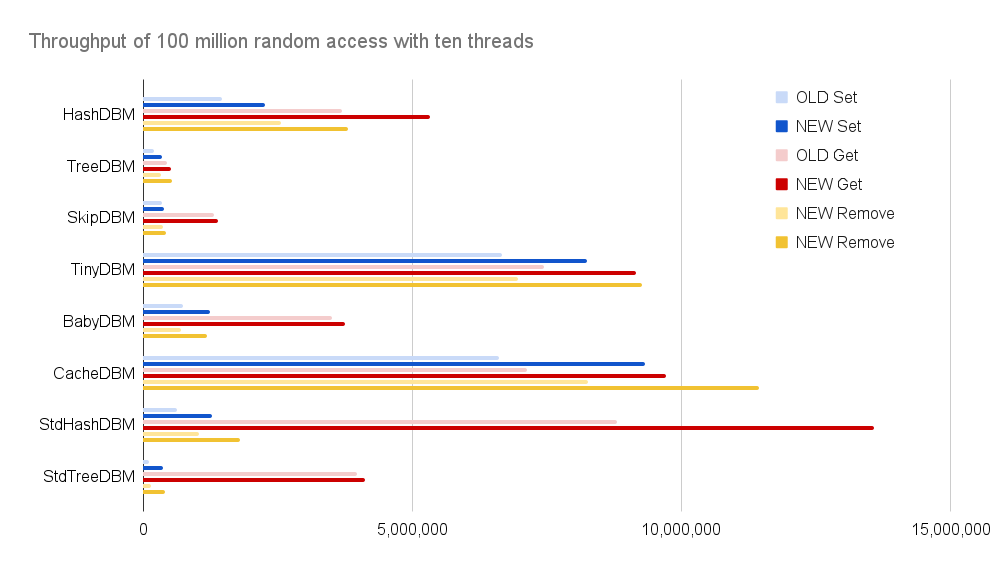
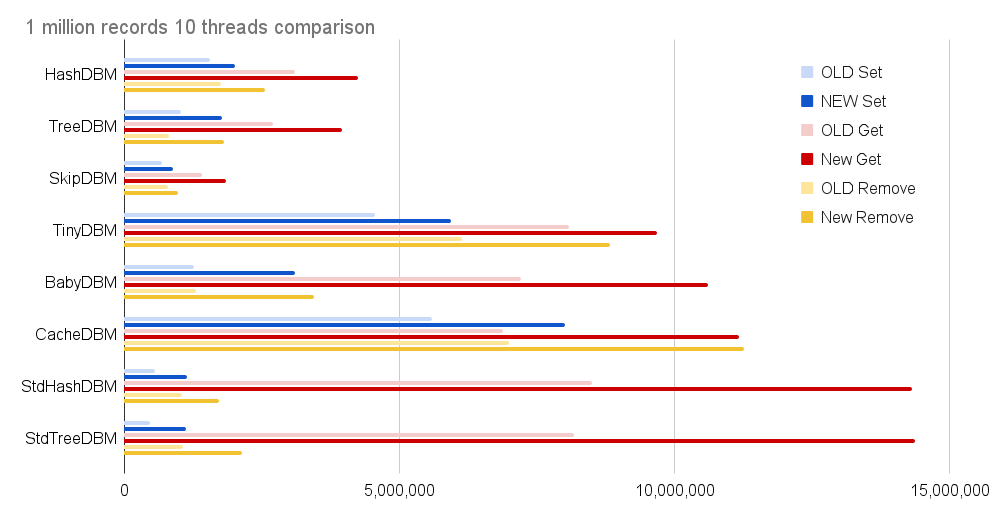
0.5.30と1.0(=0.5.53)を比較して、どれだけスループットが上がったかを見てみよう。シーケンシャルアクセス100万回の比較結果はこうなる。
| OLD Set | NEW Set | OLD Get | New Get | OLD Remove | New Remove | |
| HashDBM | 1,555,369 | 2,015,638 | 3,103,354 | 4,247,388 | 1,747,683 | 2,549,070 |
| TreeDBM | 1,021,461 | 1,766,662 | 2,707,643 | 3,960,807 | 804,723 | 1,810,971 |
| SkipDBM | 681,302 | 876,747 | 1,413,401 | 1,851,018 | 796,121 | 979,760 |
| TinyDBM | 4,553,572 | 5,933,872 | 8,087,931 | 9,683,170 | 6,141,406 | 8,819,345 |
| BabyDBM | 1,264,084 | 3,096,330 | 7,201,758 | 10,605,335 | 1,301,187 | 3,436,732 |
| CacheDBM | 5,590,184 | 8,014,691 | 6,875,457 | 11,169,442 | 6,998,625 | 11,270,406 |
| StdHashDBM | 562,094 | 1,144,803 | 8,504,404 | 14,316,594 | 1,043,376 | 1,710,431 |
| StdTreeDBM | 455,696 | 1,124,624 | 8,170,536 | 14,376,462 | 1,072,625 | 2,130,565 |
ランダムアクセス1億回の比較結果はこうなる。
| OLD Set | NEW Set | OLD Get | NEW Get | NEW Remove | New Remove | |
| HashDBM | 1,455,223 | 2,259,227 | 3,696,996 | 5,327,723 | 2,557,264 | 3,803,961 |
| TreeDBM | 194,973 | 343,564 | 434,746 | 509,779 | 326,403 | 536,877 |
| SkipDBM | 356,575 | 393,086 | 1,322,248 | 1,381,291 | 371,399 | 418,209 |
| TinyDBM | 6,667,730 | 8,246,833 | 7,441,841 | 9,151,282 | 6,965,259 | 9,272,530 |
| BabyDBM | 730,516 | 1,239,584 | 3,501,009 | 3,754,941 | 701,922 | 1,187,900 |
| CacheDBM | 6,617,201 | 9,314,902 | 7,123,973 | 9,711,285 | 8,258,052 | 11,446,497 |
| StdHashDBM | 622,629 | 1,279,515 | 8,803,087 | 13,572,641 | 1,041,685 | 1,794,882 |
| StdTreeDBM | 115,639 | 374,263 | 3,963,233 | 4,118,937 | 138,146 | 407,559 |
どの実装でもスループットが大幅に向上している。ここ数ヶ月でいろんな最適化をしてきたが、おそらく最も効果的だったのは、ロックを標準のmutexやshared_mutexから自前のスピンロックに換装したことだろう。これはある意味では禁断の技で、ビジーループによってシステム全体の速度低下を招くリスクを負うものだ。しかし、それなりの頻度でスレッドがブロックするはずのランダムアクセス1億回のテストでも性能が向上しているので、実運用上では欠点より利点の方が多いと言えそうだ。
まとめ。Tkrzw 1.0をリリースした。その機会に、各データベースクラスの性能評価をし直して、過去のバージョンに比べてスループットが顕著に上昇していることを確認した。改めて、各実装のセールスポイントを列挙して終わりにしよう。
最高速なファイル上のデータベースが欲しいならHashDBM。規模が大きくなっても数百万QPSを叩き出す凄いやつだ。ノンブロッキングで再構築やバックアップもできる。
順序付きのファイル上の高速なデータベースが欲しいならTreeDBM。規模が大きくなると数十万QPSしか出ないが、それでもそこそこ早い。アクセスパターンに局所性がある場合はHashDBM並に早くなる。自動圧縮も便利。
順序付きの大規模なファイル上のデータベースが欲しいならSkipDBM。バッチ更新しかできないが、実メモリ容量を超える大規模になるとTreeDBMより更新性能も検索性能も高い。
省メモリかつ並列処理可能なオンメモリデータベースが欲しいならTinyDBM。メモリ消費量はstd::unorderd_mapの半分で、並列更新性能は数倍だ。あと、Appendが効率的で、転置索引の構築に便利。
もっと省メモリかつ並列処理可能かつ順序付きのオンメモリデータベースが欲しいならBabyDBM。メモリ消費量はstd::mapの半分以下で、並列更新性能は数倍だ。これもAppendが効率的で、転置索引の構築に便利。
キャッシュ用途のオンメモリデータベースならCacheDBM。時間性能はTinyDBMを凌駕しつつ、LRU削除機能でメモリ使用量を一定に保てる。
ライブラリ1個入れて使い方を覚えれば、これら全てのデータ構造が使い放題。組み合わせれば可能性は無限大。Tkrzwで僕と握手!