念願であった大阪東京キャノンボールについに成功した。経過時間は21時間50分35秒だ。機材と戦略を整えれば凡脚オジサンでもキャノンボーラーになれることを証明できた。

キャノンボール再戦の準備とGP5000 AS TR
大阪東京キャノンボールに再挑戦にあたって、タイヤをGP5000 AS TRに替えた。良路面を想定した計算上では20分遅くなるが、悪路を想定すると差は縮まると想定され、耐パンク性と乗り心地が向上したことで達成率は向上すると期待される。また、ルート選定をし、その他の準備も行った。

大阪東京キャノンボール敗北
大阪東京キャノンボールに挑戦したが、残念ながら失敗したという話。失敗の記録も重要なので、成功の記録と同じ形式で記事を書く。

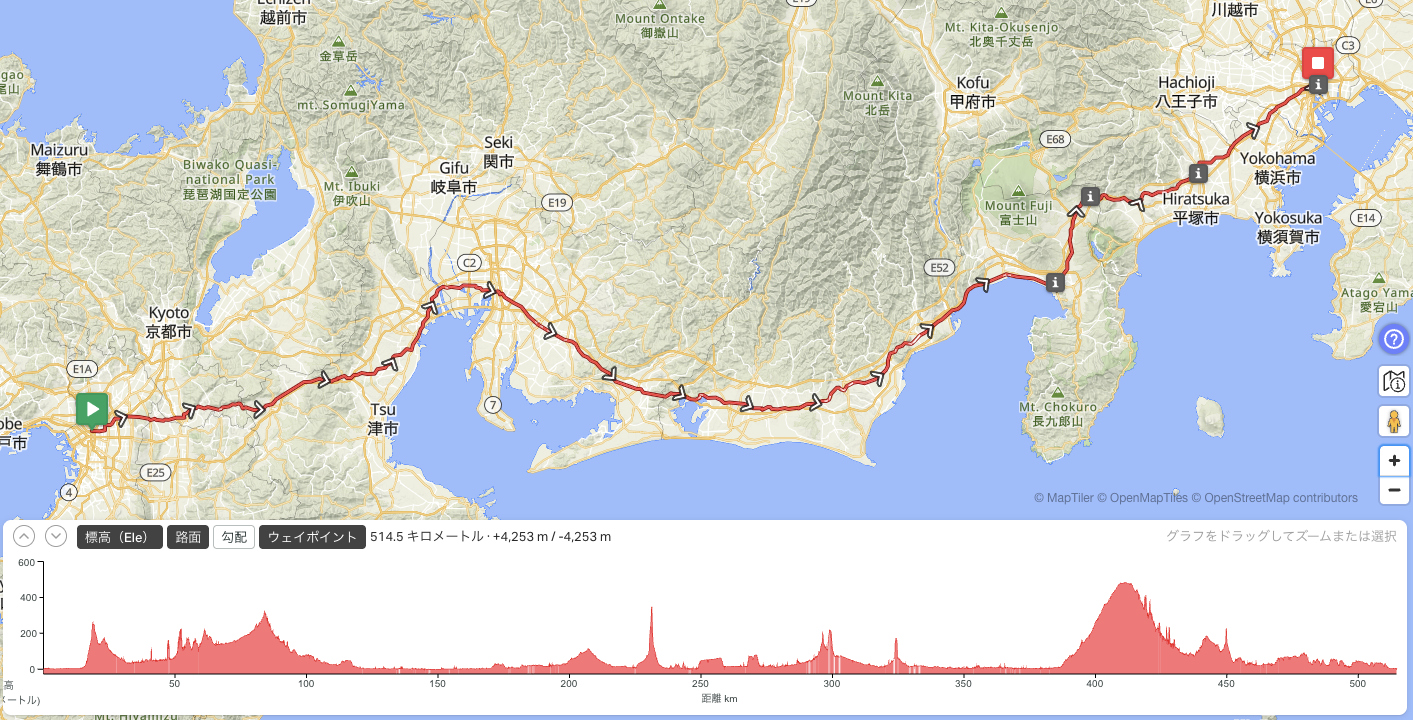
大阪東京キャノンボールの準備
東京・大阪間の片道を24時間以内に自走するというキャノンボールという慣習があるが、それをやってみることにした。その準備について詳述する。
BRM530東京600 いってこい御前崎
5回目のブルベにして、SR獲得後の裏ボスとなる600kmにブロンプトンで挑んだ。川崎からずっと海沿いに進んで鎌倉、小田原、伊東を通って伊豆の冷川トンネルを抜けて、沼津からさらに海沿いに進んで富士や静岡を抜けて御前崎まで行き、そしてほぼ同じ道で帰るというコースだ。結果としては、37時間24分で完走できた。

BRM523宇都宮600 東関東
4回目のブルべにして、SR獲得へのラスボスとなる600kmに挑んだ。宇都宮から那須塩原に北上し、そこから一気に千葉の一宮まで南下して、海沿いを走って銚子まで北上し、霞ヶ浦や筑波山の脇を通って羽生まで西進し、また北上して宇都宮に戻るという8の字のコースだ。結果として、34時間47分で完走できた。その振り返り。 
サイクリング動画用にInsta360 Ace Pro 2を購入
自転車旅をちょくちょくしている私だが、走行中の動画を車載カメラで撮りたくなった。それに見合うアクションカメラとして、DJI OSMO Action 6とInsta360 Ace Pro 2のスペックを比較した上で、後者を選んだ。そして、その使用感のレビューをまとめた。

BRM509群馬400 高崎 大洗の海を見にふらフラット
3回目のブルべにして、SR獲得への中ボスとなる400kmに挑んだ。高崎からひたすら東進して大洗の海を見て、霞ケ浦の南を回ってから西進して高崎に戻るというコースだ。結果としては、17時間43分で完走できた。BRMの1日の走行距離は400kmが最も長いと言われているので、それを完走できたことは自信になった。

ブロンプトンのリムブレーキ過熱問題の焼け石に水的対策
リムブレーキの過熱問題の対策として、ブロンプトンのフロントホイールを変えてみた。リム内幅が大きくリムハイトが高いホイールの方が熱容量と放熱性が高いと考えてのことだが、効果のほどはまだ分からん。

ブロンプトンで美ヶ原林道
天気が良かったので美ヶ原をまた走ってみたくなって、今回はブロンプトンで行ってきた。松本側から美ヶ原林道を登ったが、なかなか走り応えのあるコースだった。
