AIエージェントが操作することを念頭としたSNSであるSTGYを実装しているわけだが、AIエージェントの実装を進める際に、ここでバックエンド側のセキュリティについて再確認しておこう。AIエージェントは直接バックエンドを叩くので、ここでセキュリティの現状について確認しておくのが大事だ。
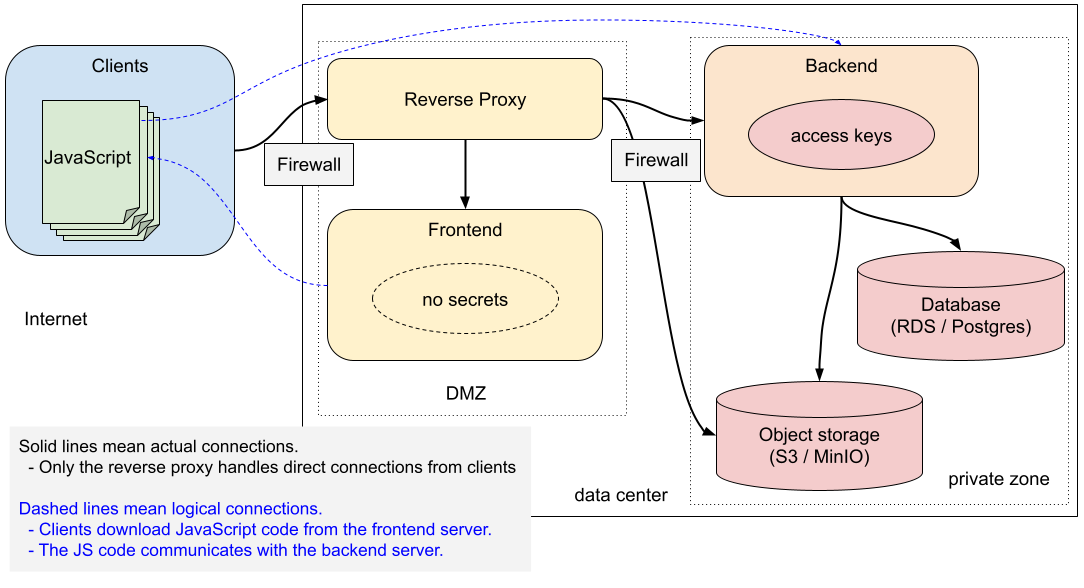
インターネットの不特定多数のユーザを対象とした全てのサービスは、常に攻撃者に狙われていると想定して実装する必要がある。STGYも例外ではない。仕事柄、OWASPというセキュリティ関連の団体が策定したASVS(Application Security Verification Standard)というガイドラインに触れることがあるのだが、そこで述べられているようなセキュリティ方策は押さえておきたいところだ。この記事では、STGYで実施している主なセキュリティ機構について説明する。
ユーザ認証
STGYはログインが必要なシステムであり、ログインした各ユーザは、自分だけが可能な操作範囲を持ち、それによって自分だけが管理できるデータを管理するようになる。当然、他のユーザになりすましてログインしたり、許可されていない操作を行ったりすることができないように計らう必要がある。
ログインはメールアドレスとパスワードによる認証を経て行う。メールアドレスとパスワードは内部のデータベースに保存される。パスワードはscryptでハッシュ化され、管理者であってもパスワードの復元はできないように計らう。メールアドレスは管理者と自分だけが見られるようにアプリケーション側で配慮する。ユーザの一覧機能等では、自分のメールアドレス以外はダミーデータが返される。
ログイン後にはセッションIDが発行されて、クッキーに埋め込まれる。セッションIDは秘密情報であり、それを知っているものはそのユーザとして認証されたものとみなす。セッションIDに紐づけられたセッション情報はバックエンド側のキャッシュに保存される。セッション情報のTTLは48時間だが、何らかの操作が行われる度にTTLが48時間に更新される。したがって、毎日の頻度で利用するアクティブユーザはログイン操作の煩雑性からはほぼ解放されるが、数日使わないでいるとログアウト状態になる。
ネットワーク
クライアント(ユーザエージェント=ブラウザ)とバックエンドサーバの間の転送経路は、SSLで暗号化して、第三者による盗聴を防ぐ。ログイン操作のために転送されるメールアドレスとパスワードや、毎回の操作で転送されるセッションIDや、各ユーザに認可された操作に伴って転送されるコンテンツは、第三者に見られてはならない。
Node.jsの多くのフレームワークはHTTPのインターフェイスを持ち、HTTPS(SSL)はサポートしない。よって、前段に置いたリバースプロクシをHTTPSの終端点とし、リバースプロクシとバックエンドサーバはHTTPで通信する。リバースプロクシとバックエンドはファイアウォール内のサブネットで通信するので、平文で通信しても盗聴の心配はない。
STGYはフロントエンドサーバ(Next.js)とバックエンドサーバ(Express)の層を持つが、両者ともファイアウォール内で稼働させる。フロントエンドはブラウザ上で動作するJavaScriptやHTMLやCSS等をクライアントに配信するだけの存在であり、その中に秘密情報は含まれない。しかし、転送経路で内容が改竄されるリスクを回避するには、フロントエンドとの通信も暗号化すべきだ。また、HTTP通信の内容とHTTPSの内容が混在すると設定が面倒になるという理由もある。S3互換の画像配信サーバであるMinIOは自力でHTTPSを喋れるが、運用を単純化するために、他と同様にリバースプロクシでHTTPSとHTTPを変換して中継する方式にする。
リバースプロクシにはCaddyを用い、サーバ証明書はLet's Encryptを使って自動的に取り寄せる。バックエンドはhttps://stgy.jp/backend/配下のURLで公開し、フロントエンドはそれ以外のhttps://stgy.jp/配下のURLで公開し、S3の画像データはhttps://s3.stgy.jp/配下のURLで公開する。
システム自体というよりは設置環境のネットワーク設定の問題だが、ファイアウォールの設定にて、外部からの接続はHTTPSの443番だけにするのが理想だ。実際には、SSH作業用に21を開けるとか、HTTPの80番も開けて即座にHTTPSにリダイレクトするとか、メールリレーの587番を開けるとかは必要に応じて許容される。重要なのは必要なポートにホワイトリスト方式で選択して開けることだ。
フロントエンド
フロントエンドのセキュリティ対策として最も重要なのは、フロントエンドのコードに秘密情報を一切置かないことだ。それによって、フロントエンドの実装者が間違って秘密情報を露出させるリスクをゼロにできる。DBサーバに接続するパスワードも、画像サーバに接続するパスワードも、外部のAIサービスに接続するAPIキーも、全てバックエンド側で管理する。バックエンドとの接続はユーザが入力した認証情報を使って行われるが、そこでクッキーに保存されるセッションIDのみが、クライアント側で保持する秘密情報となる。クッキーにはHttpOnly属性がつけられるので、フロントエンドのコードでクッキーを見ることができない。ログイン後のバックエンドとの通信で勝手にクッキーにセッションIDが付与されるので、フロントエンド側では認証関係のセキュリティについては気にしなくて良い。
なお、クッキーの設定はバックエンド側の/authエンドポイントで行うが、属性としてHttpOnly=true(JavaScriptコードからのアクセス拒否)、Secure=true(HTTPでの利用拒否)、SameSite=strict(外部サイトから流入での利用拒否)を必ず付ける。なお、SameSite=Laxがブラウザのデフォルトだが、それは外部サイトから特定の投稿やユーザプロファイルへの直リンクでのGETでクッキーを読み出すためである。GETで更新をしないなら、直リンクでセッションIDを使ってもCSRFは起きない。しかし、今回はより厳しいStrictにした。ほとんどのページはCSR(client side rendering)方式であり、ブラウザ上にHTMLを描写して、そのHTMLから呼び出されたJavaScriptのコードからバックエンドを叩くので、直リンクによるHTTPレスポンスのコードからバックエンドを叩くということがない。サイトのトップページと各記事の外部公開用ページだけはSEO対策でSSR(server side rendering)方式を採るが、セッション情報を使う一部のコンポーネントのみをCSRにすることでこの問題を回避している。
開発中はHTTPで動作確認するので、クライアントとの接続がHTTPの場合はSecure=trueを付けてはならない。しかし、本番環境でもリバースプロクシがHTTPSを終端させて、バックエンドにはHTTPのリクエストが来るので、そのままだとバックエンドのExpressがHTTPSの接続であると認識できない。そこで、app.set("trust proxy", 1) などとして、リバースプロクシから来るX-Forwarded-Protoヘッダの中身を見て、1ホップ内の接続がHTTPSであればSecure=trueを付けるようにする。
ユーザプロファイルの編集、記事の投稿、画像の投稿などの更新操作のUIにおいて、クライアント側でもデータサイズや形式の検証を行う。必須の属性で空文字列を許容しないとか、長すぎるデータを禁止するとか、サポート外の画像形式を禁止するとかである。ただし、それらは無効な操作を早めに検知してユーザに通達するというユーザビリティのための機能であり、セキュリティの機能とはみなさない。セキュリティ対策の本丸はあくまでバックエンド側である。
ネットワーク構成でDMZを設ける場合、リバースプロクシとフロントエンドサーバだけをDMZに置き、残りは内部ネットワークに隠蔽する。フロントエンドサーバには秘密情報が一切に無いので、フロントエンドサーバが乗っ取られた瞬間には、データの漏洩や損失は起きない。フロントエンドサーバのコードを書き換えられれば、ユーザからセッションを盗めることになるので、その後にアクセスしたユーザのデータは盗まれてしまう。しかし、その脅威はリバースプロクシを乗っ取られた場合も同じであり、フロントエンドとリバースプロクシの間をファイアウォールで隔離する必要性は薄い。フロントエンドを踏み台にされて内部ネットワークを荒らされるリスクを緩和するためには、フロントエンドはDMZ側にあった方がよい。一方、バックエンドはDBのアクセスキーを持つので、内部ネットワーク側に置いた方が良い。DBやその他の依存サービスは当然ながら内部ネットワーク側に置く。
DMZがあろうがなかろうが、ネットワーク上の全てのホストは、必要最低限のポートのみを公開し、必要最低限のサービスのみを起動させるべきだ。また、DMZあるいは内部ネットワークに侵入された場合にHTTPの平文を見られる事態を厭うのであれば、全ホスト間の通信をSSLで守ることになる。その際には自己証明書またはプライベートCA署名の証明書を使うことになる。その分だけ運用の手間や実行コストが上がるので、どの程度のセキュリティ要求があるかによって実際の構成を決めることになる。
エンドポイントでの入力検証
バックエンド側の視点で見ると、フロントエンドは単にクライアントがバックエンドAPIを叩く準備をするためのユーティリティでしかない。フロントエンドに頼らずともクライアントはバックエンドのAPIを叩けるので、フロントエンドでのセキュリティ対策というのは全く当てにしない。よって、バックエンドのAPIに渡される全てのデータは、その時点で妥当性検証(validation check)をする必要がある。文字列の全ての入力データは、UTF-8として妥当であることを確認した上で、UnicodeのNFC(正準等価合成)正規化を行う。そのうえで、エンドポイント毎パラメータ毎にルールベースの検証を行う。以下に代表的な検査項目を上げる。
- 新規ユーザ登録(POST /signup)
- emailの書式が正しいか
- passwordの長さが適正か
- 管理者によるユーザ作成(POST /users)
- ログインしていて、ログインユーザにadmin権限があるか
- emailの書式が正しいか
- passwordの長さが適正か
- introductionの長さが適正か
- ユーザプロファイルの更新(PUT /users/{id})
- ログインしていて、対象のプロファイルがログインユーザのものか
- introductionの長さが適切か
- 新規投稿(POST /posts)
- ログインしているか
- contentの長さが適切か
- tagsの数と長さが適切か
- 投稿の更新(PUT /posts/{id})
- ログインしていて、対象の投稿がログインユーザのものか
- contentの長さが適切か
- tagsの数と長さが適切か
検証とは別に、主に美観のための正規化処理も行う場合もある。1行であるべきデータから改行と行頭行末の空白を削ったり、複数行のデータからは末尾の改行をや行末の空白を削ったりする。
エンドポイントの入力検証とは別に、データベース層でも入力データの最終確認を行う。ユニーク制約やVARCHARの長さ制約等のスキーマレベルの検査が最後の砦となる。その前段として文字列の書式や長さや数値の変域を検査する場合もある。
バックエンドでのスロットリング
パラメータが正しくても、悪意のあるユーザに大量の更新操作をされると、システムの正常動作が滞ることになる。よって、更新系の全ての操作には、スロットリングが施される。すなわち、一定期間に許容される操作の頻度やデータ量に上限を設け、それを超えるリクエストはエラーとする。操作数やデータ量はRedisのキャッシュで管理している。
- 新規ユーザ登録 : グローバルに、1時間に60回
- ユーザの更新全種(プロファイル更新、フォロー、ブロック) : 各ユーザで、1時間に合計60回、総データ量100万文字
- 新規投稿または投稿更新 : 各ユーザで、1時間に合計60回、総データ量200万文字
- イイネ : 各ユーザで、1時間に合計60回
- 画像投稿 : 各ユーザで、1時間に合計60回
メール送信機能にも独自のスロットリングがある。
- 同一アドレスへの送信 : 1分間に2通まで
- 同一ドメインへの送信 : 1分間に10通まで
- 全体 : 1分間に100通まで
画像のデータ量の制限は、S3への画像登録時に行う。各画像で10MBまで、各ユーザ各月の合計容量が100MBに制限する。
デフォルトだと小規模サイト用の保守的な設定になっている。私のデモ環境で予期せぬトラブルが起きるのを避けたいからだが、STGYをベースに何かやろうとするかもしれない多くの小規模サイトでは、このくらいの設定が安全だろう。
回数やデータ量とは別個に、利用時間によるスロットリングも行う。操作の内容に関わらず、成功時には、その実行にかかった消費時間をキャッシュ上で加算していく。ユーザIDと日付でキーを作り、TTLを24時間にするので、操作の種類や回数に関わらず、ユーザ毎のレコード数は2つで済む。消費時間の合計値が閾値を超えた時点で、日付が変わるまでそのユーザは何もできなくなる。ネットワークエラーなどで操作に失敗した場合には消費時間を加算しない。閾値は180秒程度にしておくと、普通のユーザが引っかかることはまずないだろう。それでいて、攻撃者による負荷を迅速かつ自動的に食い止められる。
ユーザ単位スロットリングを施したとしても、予めペース配分をしつつ大量のユーザを作っておいてから、それらで一気にデータを登録するという攻撃は成立してしまう。IPアドレスでスロットリングをするにしても、DDoS攻撃には敵わない。そのレベルの敵が表れたなら、別途に対策システムを導入する必要があるだろう。アクセスログから攻撃パターンを検知して早期検出する機能と、該当のユーザや投稿を自動的に消して復旧する機能を持つことになるだろう。
JavaScriptのクロスオリジン制約
バックエンドサーバには、以下のCORSの設定がある。クライアント側でJavaScriptのfetchメソッドを発行した際には、発行元であるフロントエンドのサイトのURLを「Origin: https://stgy.jp」ヘッダとして埋め込む。それを検知して、レスポンスに「Access-Control-Allow-Origin: https://stgy.jp」や「Access-Control-Allow-Credentials: true」を付けるのがこのCORS設定である。
- origin: https://stgy.jp
- credentials: true
発行元のクライアントは、レスポンスにCORSヘッダがあると、クロスオリジンのリクエストであっても、バックエンドがフロントエンドへのデータ送信を認可しているとみなす。結果としてfetchメソッドはレスポンスを読み込むことができるようになる。なお、CORS設定はクロスオリジンの場合にのみ意味があるので、バックエンドのエンドポイント「https://stgy.jp/backend/...」がフロントエンドと同一ホストにあると見せかける今回の構成では、実はCORS設定は不要である。もしバックエンドを「https://backend.stgy.jp/...」などとして運用するならば、CORS設定が必要になる。
最近のブラウザ側が持つクロスオリジン通信のセキュリティ要件を満たすためにCORS設定は存在する。つまり、CORS制約はバックエンド側のセキュリティ対策ではなく、最近のブラウザをクライアントとしてサポートするための要件である。例えば、サブドメインhttps://wp.stgy.jpで運用しているプラグインにXSS脆弱性があったとしても、ブラウザCORS制約を実装していて、バックエンドの応答でオリジンを「https://stgy.jp」に制限している限り、攻撃者はバックエンドからのデータを読むことができない。クロスオリジン制約をサポートしないブラウザで何の意味もないことになるが、STGYのJavaScriptが動かせる現代的ブラウザは例外なくサポートしているので、そうでないケースを想定することにあまり意味はない。
メールアドレスの確認と隠匿
新規ユーザを登録する際には入力したメールアドレスに実際にメールを送り、その文面に記載されている確認番号を入力させることで、ユーザがそのメールアドレスの所有者であることを確認する。同様にして、登録したメールアドレスを変更する際には、新しいメールアドレスに確認メールを送信して、ユーザがそのメールアドレスの所有者であることを確認する。ユーザがそのアドレスの所有者であるならば、パスワードリセット機能で使う確認番号をそのメールアドレスに送ることも許容できる。
STGYは匿名のSNSである。実名を晒したい人がそうするのは自由だが、そうでない人は、自分がSTGYに登録していることすら、第三者に知られてはならない。STGYはOSS製品なので、それを使って、誰かがデートサイトを運営するかもしれない。その際に、登録者が漏れては困るだろう。ところで、既存のメールアドレスを指定してユーザ登録しようした場合に、「そのメールアドレスは既に登録されています」というエラーを表示するサイトが大手でもたまにある。それはメールアドレスが登録されていることを第三者に暴露していることになるので、明白なセキュリティリスクと考える。
この問題を回避するためには、重複したメールアドレスを指定したとしても、あたかも正常に動作しているかのように振る舞わねばならない。「確認メールを送信しました」と表示しつつ、確認メールは送信しない。より正直に書くなら「もし指定のメールアドレスがまだ登録されていない場合には、確認メールアドレスがそこに送信されたことになります」なのだが、長いので勘弁してもらう。メールアドレスを変更する際にも同様の隠蔽を行う。
任意のメールアドレスにユーザ登録確認メールを送りつけられるというのは、潜在的なセキュリティリスクと言える。サイトの機能に障害が起きるわけではないが、多数の受け取った側は迷惑に思うだろうし、stgy.jp発のメールが各社のメールサーバでスパム判定される原因にもなる。スロットリングによる緩和策は設けているが、上限以下の頻度でも長期的に送られれば問題になる。これに関しても、より上位の検知システムが必要になるかもしれない。
XSSとSQLインジェクション
フロントエンド側でレンダリングや実行がなされるHTMLやJavaScriptにユーザ指定のコードが埋め込まれるXSS(クロスサイトスクリプティング)攻撃を避けねばならない。XSSに関しては、普通にNext.jsとReactの流儀に従っている限りは、まず起こらない。外部取得のデータをHTML内に埋め込む際には必ずプレースホルダを使うというのを徹底するし、そうせざるを得ないフレームワークになっている。唯一注意が必要なのは、ユーザプロファイルや投稿記事の本文のMarkdownをHTMLに変換したものを埋め込む機能である。そこに関しては他よりも厳重にXSSが起きないかを確認している。例えば、アンカーのURLは「javascript:」で始まるようなな危険な文字列を禁止するブラックリスト方式ではなく、「/」や「https://」で始まってURLとして適格なパターンにマッチするもののみを許可するホワイトリスト方式にしている。
万が一、XSSが発生した場合、機能が侵害されるのはクライアント(ブラウザ)である。たまに勘違いする人がいるが、XSSが起きても、フロントエンドサーバは侵害されない。フロントエンドサーバはクライアントにHTMLとJavaScriptを送信した時点で役目を終えている。XSSはクライアントで実行されるJavaScriptの動作を不正にして、セッション情報を使ってバックエンドに対して不正なリクエストを送ることになる。その結果として、そのユーザの権限で、不正な操作が行われる。そのユーザの権限で参照できるデータが盗まれ、そのユーザの権限で更新できるデータが壊される。バックエンドサーバが侵害されるわけでもないが、騙されてデータを開示したり破壊したりすることにはなる。
バックエンド側SQL文を組み立てて実行する際にも、外部入力由来の任意の文字列が実行されないように、プレースホルダを使うのを徹底する必要がある。普通にプレースホルダを使っていれば問題ない。経験上、問題になりやすいのは、ORDER BY句の条件となる属性名にユーザ由来の文字列をそのまま指定することだ。ORDER BY句に限らず、SQL文内の属性名を任意指定されるのは明白なセキュリティホールなので、前段で事前に定義した文字列のどれかに読み替える処理を入れなければならない。その点を踏まえて、実行されるSQL文の全部を棚卸しすることが望ましい。EXPLAIN文で全SQLの実行計画を確認するついでに、SQLインジェクションの確認もするべきだ。
SQLインジェクションが起きた場合に侵害されるのは、バックエンドサーバとデータベースサーバの両方だ。pl/SQLのコマンドなどが不正に呼ばれると、バックエンドサーバ上で不正にファイルが作られる可能性がある。権限設定によっては任意のシェルスクリプトが実行されてしまうので、バックエンドサーバ上でかなり深刻な被害が出て、そこを踏み台にされて他のサーバが侵害される可能性もある。任意のSQLクエリが実行されれば、DB全体のデータが漏洩したり破壊されたりする可能性がある。
システムのどこにも脆弱性がないとしても、大量の負荷をかけるSQL文を実行させるDoS攻撃を受けることが考えられる。例えば、投稿一覧の取得操作でLIMITに1000万などの大きな数を指定することで、データベースとネットワークに多大な負荷をかける攻撃が考えられる。リスト系の全ての操作においては、LIMITを100を上限にすることで、負荷低減を図っている。リスト系以外の全ての公開APIの操作は、単一もしくはごく少数のレコードを対象にしたクエリしか実行されないようにしているので、単一のクエリで大きな負荷をかけることは不可能である。クエリを大量に実行しようとする試みに対してはスロットルで対処する。
ロギング
サービスの運営を妨害した攻撃者や、サービス上で違法行為を行ったユーザに対しては、アクセス元を特定して法的措置を取ったり、捜査機関に情報提供したりする必要性が生じる。そのためには、日時とクライアントのIPアドレスと操作内容を紐づけてログに記録しておく必要がある。
ログイン前の攻撃に関しては、基本的にはGETで負荷をかけてくるだけなので、リバースプロクシ側で日時とIPアドレスとリクエスト行を保持しておけば十分だ。ログイン後の攻撃に関しては、バックエンド側でログを取る。その前提として、リバースプロクシからバックエンドにクライアントのIPアドレスを伝達する必要がある。慣習に基づくと、プロクシを中継されてきた一連のIPアドレスのチェーンはX-Forwarded-Forに入っている(そのようにCaddyを設定する)。バックエンド側で app.set("trust proxy", 1) を実行すると、リクエスト構造体のip属性には、1ホップ前のCaddyにとってのクライアントのIPアドレスが設定される。2ホップ以前のIPアドレスのチェーンは管理下になく信用に値しないが、捨てずに別途記録しておく。
バックエンド側のログは監査と追跡に必要なもののみに絞る。ユーザの作成・更新・削除と、投稿の作成・更新・削除は確実にその対象にすべきだ。フォローやイイネやブロックを記録するかどうかは要件によるが、大したデータ量でもないので、記録しておいて損はない。よほどの機密情報を扱うシステムでもないかぎり、閲覧行為を記録する必要はない。いずれにせよ、全てのエンドポイントでログ記録用の関数を呼ぶようにしておいて、サーバ全体のログレベルに応じて実際の記録の是非を決定することになる。
なお、上述した監査のログと、サービス管理や性能分析に使う通常の運用ログは、別個のロガーオブジェクトと別個のログレベルを使ってを管理する。開発環境では監査ログは全く取らず、運用ログはデバッグレベルにするのが普通だ。本番環境では監査ログは規定レベルで記録し、運用ログは警告レベルにする。記録したログをどこに転送してどの程度の期間保管するかは実運用の要件に応じて別途定義する。
情報設計によるリスク軽減
STGYにおいては、各ユーザが入力したメールアドレスとパスワード以外のデータは、他の全ての登録ユーザから閲覧可能な状態になる。ダイレクトメッセージ機能はなく、一部のメンバーに閉じたコミュニティ機能もない。誰かにブロックされたユーザも、イイネや返信などの書き込み操作が禁止されるだけで、閲覧が制限されるわけではない。STGY上でユーザから預かっているデータは誰でも平等に閲覧できる。そして、STGYにはメールアドレスさえあれば誰でも登録できる。ゆえに、STGY上のデータの秘匿性はほぼ無い状態になっている。STGY上に乗せた情報はWeb上で全世界に発信しているのとほぼ同義だということだ。この情報設計を前提とすると、情報漏洩という概念がなくなる。もともと秘密じゃないからだ。
秘匿するべきなのはメールアドレスとパスワードだけで、パスワードは比較的強度の高いscryptでハッシュ化されている。ゆえに、たとえDB全体のデータが転送されたとしても、暴露される秘密はメールアドレスの一覧だけということになる。もちろん、それでも漏洩は許容できないことだが、リスクと賠償責任は小さい方が良い。
逆に、企業や学校などの閉じたコミュニティで運用する場合には、部署単位やゼミ単位などの情報空間を分けるのが必須になる。その場合、全てが公開情報という建付けは諦めて、要件に応じたカスタマイズをするしかない。閉じたコミュニティであれば攻撃されるリスクが必ずしも下がるとまでは言えないのが辛いところだ。インターネットに接続していれば、どこからだって攻撃されてしまう。イントラネットでの運用なら少しはましだが、内部に悪意のあるユーザが居ないという保証はどこにもない。
被害からの回復
SNSのシステムが攻撃された場合に起こる被害を想定し、そこからの回復策を事前に検討しておくことが重要だ。以下に、想定被害ごとの回復策を検討する。
- データ損失
- 不正/乱用データの混入
- システム停止
- 原因究明後、速やかにシステムを再起動する。ただし、同一構成のシステムをそのまま起動しても再び攻撃される可能性があるので、機能を絞ったセーフモードを用意するのが理想。
- ダウンタイムを短縮するためには、対策後のシステムのデプロイを迅速にする必要がある。自動デプロイの整備が重要。
- 情報漏洩
- 外に漏れた情報を無かったことにする手段はない。謝罪の上で、補償などの措置を検討するしかない。
- 混乱と信頼失墜
- 被害状況の把握と原因の究明に努め、その結果をユーザや関係者に報告する。また、再発防止策をまとめる。
2FAとパスキー
現状では、2FA(二段階認証)はサポートしていない。2FAはセキュリティ機構の一部ではあるが、ユーザ認証の機能であって、システムの堅牢性に関する非機能要件ではない。2FAがないことでユーザが認証情報を漏洩させるリスクが上がるが、それはシステム外の出来事だ。十分な強度のパスワードを設定して、それを適切に管理することは、ユーザの責任だ。2FAを使ったとしても、ノートPCを開いたまま離席するなどの重過失があれば、不正利用をされてしまう。システム外で何があろうが、システムとしての堅牢性の問題ではない。この区別は重要だ。
ただし、ユーザもシステムの一部であるとみなせば、2FAはシステムの堅牢性を高めるための機能要件として上がってくる。実際のところ、大手のサービスの多くは2FAをサポートしている。ユーザの不注意で認証情報が漏れたとしても、2FAがないことを理由に、理不尽にも運営者側が訴えられる可能性がある。2FA機能があるのに使わなかったのならば、それはユーザ自身の選択ということになり、過失の全てをユーザに帰することができる。よって、ユーザ保護および運営者である自分の保身のために、早晩2FAに対応せねばならない。
最初はTOTP(時間式ワンタイムパスワード)を実装するつもりだったが、思い直した。TOTPのデバイスを紛失した時の救済策としてリカバリコードによるログイン機能をサポートすることになるが、むしろそれがセキュリティ上の脅威になるからだ。ここで、なぜ2FAが必要なのかに立ち返ってみよう。それは、パスワードをちゃんと管理しないユーザが居るからだ。従来のパスワード認証だけでも、パスワードがちゃんと管理できてさえいれば、セキュリティリスクにはならない。しかし、現実的には、推測されやすいパスワードを使ったり、複数のサイトで同じパスワードを使いまわしたり、付箋にパスワードを書いてディスプレイに貼ったりする人達が一定数居る。そのような人達は、かなりの確率で、リカバリコードを書き込んだpassword.txtといったファイルをデスクトップに置くことだろう。リテラシが低い層に最大の効果があるTOTPの存在が、実運用上はリカバリコードを発行せざるを得ないので、彼らをかえって危険に晒すことになりかねない。
その問題を見事に解決するのがパスキーである。パスキーはTOTPと違って公開鍵認証方式であり、秘密鍵はクライアント側のキーストアで安全に管理される。クライアント(ブラウザ)側の機能で、秘密鍵はGoogleやMicrosoftやAppleのクラウド上のキーストアにもバックアップされるので、リカバリコードを発行する必要がない。サーバ側は公開鍵しか持たないので、サーバ側から認証情報が漏れることも原理的にない。クライアントは認証情報を送信する際に発行元を確認するので、フィッシングサイトに入力することもできない。ある程度リテラシの高いユーザでも巧妙なフィッシングサイトには引っかかる可能性があるので、その点でもパスキーは有効だ。
パスキーは、適切なライブラリさえ使えば、サーバ側の実装も簡素で済む。DBに追加するテーブルは以下のものだけだ。
CREATE TABLE passkeys ( credential_id BYTEA PRIMARY KEY, -- パスキーのID(ブラウザの認証器が生成) public_key BYTEA NOT NULL, -- 認証器の公開鍵(ブラウザの認証器が生成) sign_count INTEGER NOT NULL, -- 署名カウンター値 rp_id VARCHAR(255) NOT NULL, -- "stgy.jp" 決め打ちなので、要らんかも owned_by BIGINT NOT NULL, -- パスキーの所有者のユーザID key_name VARCHAR(100) NOT NULL, -- 一覧表示で使う名前 created_at TIMESTAMPTZ NOT NULL -- 一覧表示で使う登録日時 );
あとは、バックエンドに以下のエンドポイントを足せば良い。既存のパスワードを消すエンドポイントも別途用意する。
- POST /passkeys/register/start:パスキー登録用のチャレンジを生成
- POST /passkeys/register/verify:クライアントからの応答を検証し、DBに保存
- POST /passkeys/auth/start:ログイン用のチャレンジを生成
- POST /passkeys/auth/verify:クライアントからの応答を検証し、セッションを確立
- GET /passkeys : 自分のパスキーの一覧を返す
- DELETE /passkeys/{credentialId} : 該当パスキーを削除する
ユーザ登録とパスキー登録を同時に行うサインアップのエンドポイントも欲しくなる。
- POST /signup/passkeys/start : チャレンジ生成と確認メール送信を同時に行う
- POST /signup/passkeys/verify : メール記載の確認番号とその他の応答を検証し、ユーザとパスキーをDBに保存
パスキーをサポートしたとして、それをどう運用するかには、選択肢がある。ユーザ毎に、ログインする毎に、パスワード認証とパスキー認証のどちらでも選べるようにするのが現状では普通だろう。新規に運用開始するなら、非対応の古いブラウザは切り捨てて、パスキーに一本化するのも合理的だ。OSS製品のパッケージとしては、STGY_FORCE_PASSKEY=true/falseなどという環境変数で切り替えられるようにする。システムがパスキー強制状態なのにパスワード認証したユーザは、パスキー作成以外の操作ができないようにする。ただし、パスキーだけで運用しようとすると、AIエージェントもWebAuthnプロトコルを実装する必要が出てくるが、それはかなり面倒くさい。AIエージェント用に、サーバ側で生成した強いパスワードであるAPIキーによる認証機構を設けるのが現実的だろう。
コンテンツセキュリティ
システムの継続稼働を目的としたシステムセキュリティの方策について数多く述べたが、それだけでは十分ではない。TwitterやFacebookなどの大手SNSがより多くのリソースを投じているのは、むしろコンテンツセキュリティの方だ。正常稼働しているプラットフォームの上で起こる不法行為や権利侵害やその他のトラブルへの対策を考えねばならない。それは機械的にできることではないので、システムセキュリティよりもコンテンツセキュリティの方がずっと難易度が高い。
最初にすべきは、利用規約の策定である。これは真面目にやると非常に大変だ。既存のサービスのものを参考に作ることになるのだが、そのままコピペするわけにはいかず、自分のサービスの機能や方針に合った文面に直さねばならない。コンプライアンスはもちろん、巷の慣行やユーザの反応も鑑みて内容を詰める必要がある。STGYはAIエージェントが勝手に行動するシステムなので、それに応じた項目も設ける必要がある。規約とは別に、トラブルが起きた際の内部ガイドラインも作っておくことが望ましい。その際には、プライバシーとか表現の自由とかいった微妙かつ物議を醸しやすい内容にも、典型的なケースを洗い出して、判断を決めておく必要があるだろう。
その上で、トラブルの抑止・緩和・検出・対処を目的とした機構を順次導入していくことになる。それらは総じてコンテンツモデレーション機能と呼ばれる。現状では、めぼしい機能がない。フォローしていないユーザからの返信やイイネを禁止するblock strangersフラグと、任意のユーザをブロックする機能は、ある意味ではコンテンツモデレーションになっている。しかし、それだけでは足りない。投稿やユーザの規約違反を通報する機能がまずは必要だろう。そうなると、通報を集計して仕訳けして対処する仕組みも必要になる。対処にあたっても、ユーザや投稿をいきなり消すのではなく、警告・凍結・削除とかいった段階的な手順が踏めるように制度設計する必要がある。機械的に対処できない問題に関しては、監視ツールを作って人間が対処することになる。大規模になるとそれもやっていられなくなるので、AI活用を検討することになるだろう。
まとめ
率直で教科書的なSNS実装を作るSTGYプロジェクトにおいて実現すべき、率直で教科書的なセキュリティ要件をまとめた。盗聴から通信を保護するためのSSL暗号化、DoS攻撃からデータを保護するためのバックエンドでの入力検証、悪意ある外部サイトからユーザを保護するためのクッキー設定とCORS設定、XSSやSQLインジェクションなどの実装の不備の抑止、攻撃者に責任を取らせるためのロギング、などなどの総合的対策を取っている。それでも被害は起こり得るので、リスク低減と回復策についても検討しておくことが望ましい。2FAに関してはまだ実装していないが、パスキー対応の設計を進めているところだ。コンテンツセキュリティについてはほぼ白紙なので、おいおい考えていきたい。
機能だけではなくてシステムセキュリティのことをちゃんと考えたOSSのSNSシステムを巷で見ることは少ない。現時点でも、STGYのリファレンス実装としての価値はそこそこ高いのではないか。さらに、コンテンツセキュリティの基本的な機能まで実装できれば、大学の講義での教材になってもおかしくない位置づけになるだろう。面倒くさいと思いながら作っているセキュリティ関係の機構ではあるが、真面目に考えていたらだんだん面白くなってきた。