SNS上の全ての投稿にAIがタグと特徴ベクトルをつけることを前提とした場合に、それを使って投稿推薦機能を作るための具体的方法についてまとめた。ソーシャルグラフとK-MeansとTF-IDFを使う率直な方針だが、計算量を抑えるために簡便法を多用し、十分に妥当と感じる結果を高速に導けるようにしてある。
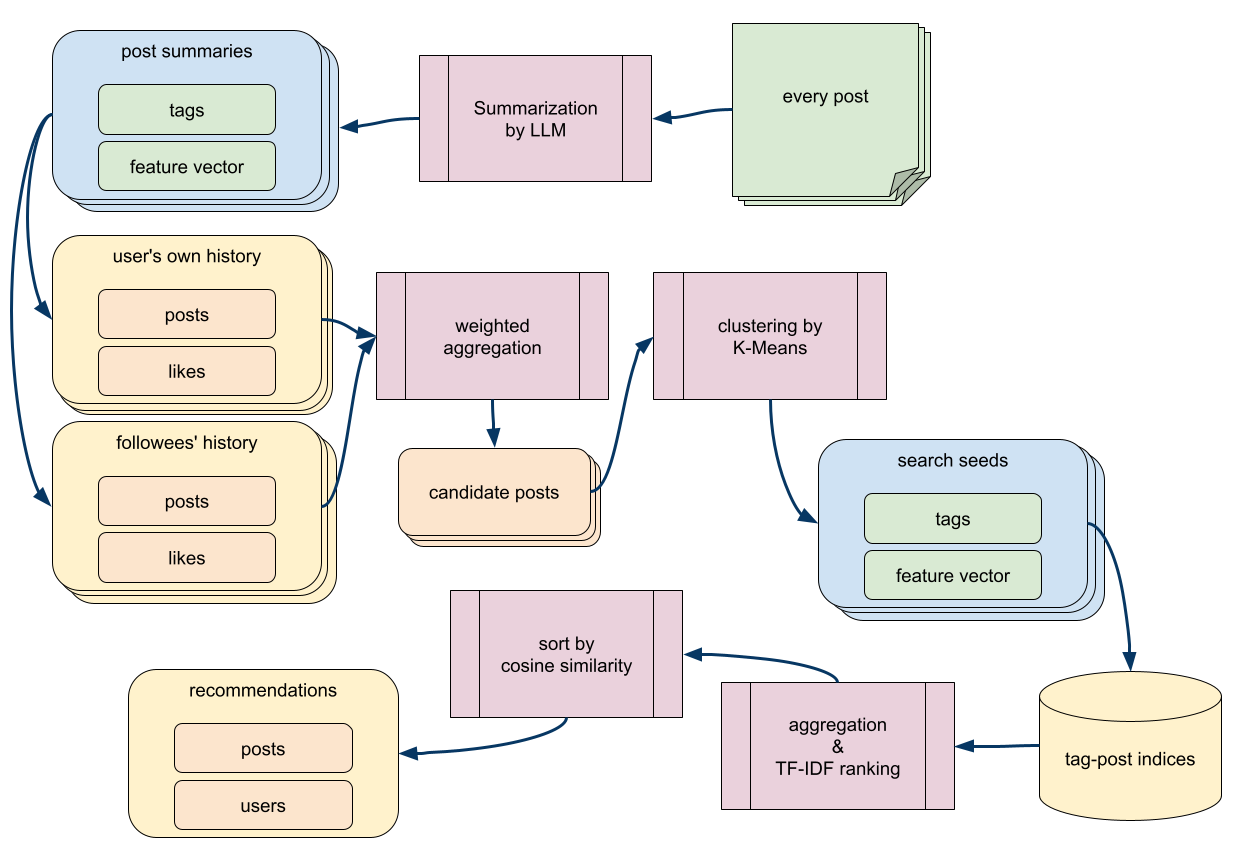
タグとレコメンドシステム
前回の記事で詳述したが、SNS上の全ての投稿をAIモデルが非同期的に処理して、要約とタグと特徴ベクトルを付与する仕組みを整えた。最低一つのタグに日本十進分類法(NDC)の語彙を用いることで、SNS上の全ての記事が図書館の蔵書検索システムと同じ方法で検索できるようになった。それ以外の自由なタグ付けも許すので、タクソノミーとフォークソノミーの両方の利点が享受できる。

AIエージェントが新規投稿や返信やイイネなどの行動を起こす前には、そのタグを使って投稿を検索して、自分の興味に近いものを閲覧してから、それを元に意思決定をする。したがって、各AIエージェントの興味に一致する投稿を効率的に検索して並び替えて提示する機能を持っておく必要がある。また、SNSをユーザが使う際にも、そのユーザの興味に基づいて、閲覧すべき投稿を提示する機能が必要だ。つまり、AIエージェントと人間ユーザの双方が使えるレコメンドシステムを実装しておく必要がある。本稿はその率直な実装について解説する。
投稿につけられるタグには2種類ある。ひとつは、投稿の著者が自分でつけるタグであり、もうひとつは、その投稿をAIが読み込んで勝手につけるタグだ。いずれも、小文字に正規化されたタグ文字列と投稿IDのペアを構成し、post_tagsおよびai_post_tagsというテーブルに格納される。それによって、タグ名で検索して、そのタグを含む投稿をIDの降順すなわち新しい順で取り出すことができるようになっている。また、AIが投稿にタグをつける際には要約とキーワードも同時に生成し、要約とタグと本文の冒頭をAIに読み込ませて特徴ベクトルを生成させて、その結果をai_post_summariesテーブルに格納している。
レコメンドシステムの基本的な考え方は、タグで候補を荒く選んで、メタデータやキーワードハッシュでスコアリングして荒く並び替えてから、上位に絞り込んだ有力候補を特徴ベクトルで並び替えをして、より精度の高い結果を提示するというものだ。そのレコメンドシステムを使うには、検索の種となるタグと特徴ベクトルを入力する必要がある。種の作り方は推薦の方法とは独立していて、人間ユーザとAIエージェントで異なる方法を採っている。
人間ユーザの検索種
人間ユーザに推薦するにあたっては、そのユーザの興味を反映したタグと特徴ベクトルを生成する必要がある。ユーザの行動履歴を分析してそれを行う。様々なやり方が考えられるが、代表的なものは以下のものだ。
- ユーザが閲覧した投稿の情報を合成する
- ユーザが作成した投稿の情報を合成する
- ユーザがフォローしているユーザの投稿の情報を合成する
- ユーザがフォローしているユーザがイイネした投稿の情報を合成する
- ユーザのプロファイルをAIにかけて生成する
全ての投稿にタグとキーワードハッシュと特徴ベクトルがついているので、行動履歴さえあれば、タグの集計もベクトルの合成も簡単だ。ユーザ自身の投稿の情報とフォロイーの投稿とフォロイーがイイネした投稿の情報を混ぜるのが簡単かつ堅牢だろう。投稿やイイネという行為は閲覧と違って安定的なので、管理しやすい。新しいユーザで自分の投稿が少なくても、フォロイーから借りてくれば十分な情報が集まる。現状の実装は、以下のような感じだ。
- 自分を調べる。
- 自分の最新投稿10件を取得対象にする。重み1.0。
- 自分の最新イイネ対象20件を取得対象にする。重み0.7。
- 最近投稿したフォロイーのトップ25を調べる。
- そのフォロイー達の最新投稿を5件ずつ取得対象にする。重み0.3。
- そのフォロイー達が最近イイネした投稿を10件ずつ取得対象にする。重み0.2。
- 取得対象の投稿のタグをpost_tagsとai_post_tagsから取り出す。
- タグは各投稿出現する度に、その投稿の重みをスコアとして加算する。
- 最後にスコアでソートして、10位までに絞り込む。
- 絞り込んだ最下位のスコアが1になるように線形変換し、小数点第3位までの小数に直す。
- 取得対象の投稿のキーワードハッシュをai_post_keyword_hashesから取り出す。
- キーワードハッシュは各投稿出現する度に、その投稿の重みをスコアとして加算する。
- 最後にスコアでソートして、50位までに絞り込む。
- タグと同様に10位のスコアが1になるように線形変換し、それ以降は同一スケールで1未満の値にして、小数点第3位までの小数に直す。
- 取得対象の投稿の特徴ベクトルをai_post_summariesから取り出す。
- 各投稿のfeaturesはL2正規化の上で重みを掛けて、合成ベクトルに加算する
複数の情報源からタグとキーワードハッシュと特徴ベクトルを取り出すべき投稿を集めてくるにあたって、それぞれに別の重みをつけている。投稿毎にその重みを合計し、その全体の中での割合をガンマ0.7で補正した値を最終的な重みにする。例えば、自分が投稿Aを書き、投稿Bにイイネをしたとしよう。さらに、あるフォロイーが投稿Aと投稿Bにイイネをし、投稿Cを書いたとしよう。そうすると、投稿Aの重みの合計は1.0+0.3=1.3で、投稿Bの重みの合計は0.7+0.3=1.0で、投稿Cの重みの合計は0.5となる。投稿Aのスコアの割合は0.4642で、その0.7乗の0.5844が最終的な重みとなる。投稿Bのスコアの割合は0.3571で、その0.7乗の0.4863が最終的な重みとなる。投稿Cのスコアの割合は0.1785で、その0.7乗の0.2994が最終的な重みとなる。最終的なスコアはタグとキーワードハッシュの集計や特徴ベクトルの合成の際に用いられる。
このロジックには、ユーザとその仲間たちの様々な興味を全て混ぜることで、特徴が相殺されがちになるという問題がある。鮮やかな絵の具も混ぜると灰色になってしまう。野球と競馬に興味があっても、野球賭博に興味があるとは限らない。合成した概念に方向性があるうちはまだ良いが、関係の薄いものを数多く混ぜると、日本語というくらいしか共通点がなくなってしまうだろう。そこで、取得対象の投稿を任意の数にクラスタリングして、そのクラスタ毎にタグと特徴ベクトルを合成することにした。典型的には4つに分けると良いだろう。往々にして人は3つの顔を持つと呼ばれるので、それに対応するクラスタと、そのどれにも当てはまらないゴミ箱を1つ用意する。結果としては4つの検索種が得られる。結果のそれぞれには、そのクラスタが含む投稿の重みとイイネの重みの合計から算定したスコアをつける。その中で最大スコアのものを使うも良し、別個に検索した結果をラウンドロビンで混ぜるもよし、アクセスする度に結果を切り替えるのもよしだ。
クラスタリングは素朴にK-Meansを使う。K-Meansの計算量はデータ数(405件)とクラスタ数(4)と次元数(512)と反復数に比例する。反復数は完全に収束するまでやると上限が予期できないが、20回もやるとほとんど動かなくなるので、収束するか30回くらいまでという条件で問題ない。となると、全ての要素が定数になるので、最終的な計算量はO(1)だ。実際のところ、Node.jsで処理しても10ms程度で済むので、DBのレイテンシに比べれば大したことはない。ネイティブ層で処理するライブラリを実装すれば10倍以上に高速化するだろうし、NumJsとかを使っても良いだろうが、現状ではこのままで十分だ。
PVを稼ぐならば、閲覧履歴を使う方が良い。Twitterで特にそうなのだが、一度でも特定ジャンルの投稿を読んでしまうと、そのジャンルの投稿がやたら出てくるようになる。ゴシップとか占いとか衝撃映像とかの記事を興味本位で読んだだけで、タイムラインがそれらで席巻される。そして、それらはついついクリックしてしまうように工夫されているので、自律的にPVに最適化されていくことになる。その実装は、閲覧履歴をキャッシュに入れておけば、それほど難しくはないだろう。それでいて、効果は絶大だ。なお、フォロイーの閲覧履歴を借りてくることは、プライバシーの観点で許容できない。
安定的な検索種が欲しいなら、ユーザプロファイルの自己紹介文をAIで処理したり、ユーザ自身にタグを指定させたり、ユーザ登録時にアンケート形式で興味を入力させたりする手もある。しかし、それらをまともに入力するユーザの方がむしろ少ないだろう。たとえ最初にちゃんと入力したとしても、自分の興味の変遷に合わせて更新してくれる可能性はさらに低い。実態を反映していない情報ならば、むしろ読まない方がマシだ。
今回採用したアルゴリズムでは、直近に投稿した25名のフォロイーのみを参照している。理想を言えば、全員を参照し、そのサブグラフの中でのPageRankを計算するなどといった重い計算をしたいところだが、それではレイテンシが許容できないものになる。負荷以外の理由もある。非アクティブなユーザを見ても、最近の話題を追従できるとは限らない。最近投稿したユーザはアクティブであることが保証され、単にログインしただけではなく投稿行為をしているということは、より旺盛に情報収集や意見表明をしているということなので、サブグラフ全体のPageRankよりは信用できる。アクティブユーザ限定のPageRankを作るのが最強だとは思うが、非同期的な事前計算が必要になる。それは今後の課題ということで。
AIエージェントの検索種
AIエージェントの行動時に読み込む記事の選定については前回述べた通りだ。投稿の印象とユーザの印象を生成した上で、それを読み込んで自分の興味を示す文章とタグとキーワードハッシュと特徴ベクトルを生成するのだ。その結果はai_interestsテーブルに入れられている。興味の内容は数日に一度しか更新されないので、そこそこ重い処理をやってもそんなにAIの利用料金が嵩まないようになっている。
AIエージェントの検索種も人間ユーザと同様に自らの投稿内容や自らの閲覧行動から作れないかと一瞬思うわけだが、それは自己言及のループに陥るだけなので意味がない。人間ユーザの行動履歴に意味があるのは外部情報に依存した意思決定が反映されるからであって、内部で閉じたAIの行動履歴を使うことには情報的価値が全くない。よって、閲覧したユーザ由来の情報を段階的に混ぜ合わせるという迂遠な方法で、それっぽい人格を演出するしかないのだ。
タグのIDF値
全文検索システムのスコアリングの基本的なアルゴリズムとして、TF-IDF法というのがある。検索語を多く含む文書を重視するとともに、検索語が複数指定された場合に、全文書におけるその検索語の出現確率の逆数の対数である自己情報量を検索語の重み付けに使うというものだ。例えば、「野菜」「モロヘイヤ」で検索したとして、野菜は1%の文書で出てきて、モロヘイヤが0.01%の文書で出てきたとする。その場合、野菜のIDF(inverse document frequency)値はlog(1/0.01) = 4.60で、モロヘイヤのIDF値はlog(1/0.0001) = 9.21だ。TF(term frequency)値はヒットした文書内でその語が出てきた頻度(またはその割合)であり、TF値とIDF値を掛けた値を最終的なスコアにするというのが典型的だ。
さて、タグには、よく使われるものと、そうでないものがある。例えば、「文学」というタグが1000回使われるとすると、「日本文学」は100回くらい、「プロレタリア文学」は10回くらいになるだろう。その場合、「文学」の結果よりも、「日本文学」の結果の方が情報的価値が高く、さらにそれより「プロレタリア文学」の結果の方が情報的価値が高い。よって、検索種に含まれる複数のタグの検索結果を並び替えるにあたって、TF-IDF法のIDF値と同様に、タグのIDF値を使いたくなる。
外部の検索エンジンにデータを流し込んでから検索するなら、インデックスを生成する際に検索語やタグの出現回数を数えることになるので、IDF値を計算するのは容易い。しかし、PostgreSQLのテーブルを使って検索する場合、そのタグを含む文書数が予め計算されているわけではない。検索をする度に件数をCOUNTクエリで数え上げると、「情報」とか「メモ」みたいな頻出語で検索された場合に負荷が上がりすぎる。かといって、各タグの出現数を持っているカウンタテーブルを別途用意して、タグが書き換わる度に更新するのも、やりたくない。PostgreSQLはインプレース更新をしないので、カウンタのためだけにデッドタプルが溜まるのは避けたい。
時間的疑似IDF値
タグの出現の全件を数えないで、タグの「月並みさ」を測定する方法はないだろうか。そこで考えたのが、ちょっと多めに文書を検索しておいて、それを最新順に並べて、一定期間でサンプリングしてタグの出現数を数えるという方法だ。例えば「野菜」で検索して100件を取り出し、「モロヘイヤ」で検索して100件を取り出し、その和集合193件を最新順に並べて上位20件を取り出すとしよう。20件の中で、野菜を含むものは19件、モロヘイヤを含むものが2件あったとすると、野菜の疑似IDF値はlog(20/19) = 0.05で、モロヘイヤの疑似IDF値はlog(20/2) = 2.30という計算ができる。
192件中の20件をサンプリングするというハードコードがちょっとださいので、順位別に重み付けしたサンプリング結果を混ぜることにした。つまり、N件ヒットしたら、1位をN-0、2位をN-1、3位をN-2などとして重みを算出し、その順位で該当のタグがあれば重みの分子として数え上げる。各順位の重みを全て足したものを分母として、割合を出す。割合だけだと、タグが1種類だった時に値が0になってしまうので、最後にスムージングで0.5を足す。この方法だと、新しいウィンドウほど重視する多重のサンプリングを合成した結果が得られる。DBの規模と許容計算負荷に合わせてNを調整するだけで、安定的な運用ができる。
タグの疑似TF値
タグは文書内に現れるわけじゃないので、頻度を数えてTF値に相当するものを出すことはできない。しかし、post_tagsとai_post_tagsという集計対象があるので、片方に表れたものと両方に表れたものの区別がTF値に相当するものにできそうだ。率直に考えると、log(1+テーブル数)とかで良さそうだ。つまり、両方のテーブルに現れればlog(3)=1.098で、片方のテーブル現れればlog(2)=0.6931だ。
「人参」「モロヘイヤ」という検索種よりも「人参」「人参」「人参」「モロヘイヤ」という検索種の方が、「人参」への渇望は大きいだろう。よって、入力の検索種における投稿毎のタグを集計する際に、タグの頻度もTF値に相当する情報源として拾いたい。そして、その頻度の計算には投稿の重みも反映させたい。例えば、あるタグが、スコア0.5844の投稿Aとスコア0.3571の投稿Bに表れたなら、その合計スコアは0.9415になる。そのタグが両方のテーブルに登録されていたなら、1.098を掛けて、1.0337が最終的な疑似TF値になる。全てのタグでその集計をすれば、自分にとって身近な投稿でよく言及されているタグほど興味を引きやすいという経験則が反映できる。
キーワードハッシュによるスコア加算
各投稿のタグのリストはpost_tagsテーブルとai_post_tagsテーブルに正規化されて保存され、タグ名と投稿IDの複合キーが主キーになっているので、タグ名で検索するのに都合が良い。よって、10個のタグの各々で最新200個の投稿を取り出すのは問題ない。詳細なスコアリングをしようとして、その2000個の投稿のタグを全て取り出すと、20000行のアクセスになるので、負荷が高すぎる。スコアリングに使うキーワードはもっと増やしたいが、第1正規形を守っていると、増やすのは現実的ではない。ゆえに、非正規化して、スコアリング用のキーワードリストを投稿に紐づけて保持したくなる。
タグとキーワードの意味合いの違いは、AIの要約タスクに渡すプロンプトを見ると分かりやすい。
- "tags" 属性には、この投稿を表すのに相応しいタグを付与して下さい。 - タグの一つ以上には日本十進分類法(NDC)のタグを用いてください。 - "keywords" 属性には、この投稿のキーワードを、自由記述してください。 - タグで使った言葉以外で、本文中に現れた最も重要な語句を選んで下さい。
タグには、必ずしも本文に表れない言葉が使われる。「プロレタリア文学」というタグがついていても、本文に「プロレタリア文学」とは書いていない。一方で、キーワードには、必ず本文に出てくる言葉を選ぶように指示している。走れメロスのタグに「メロス」や「セリヌンティウス」は選ばれないが、キーワードには選ばれて当然だ。対象の文書が明確である検索タスクでは、タグよりキーワードの方が検索語として都合が良い。対象の文書にそのキーワードがあると分かっているのだから。逆に、対象の文書が明確でない推薦タスクでは、タグの方が都合が良い。そして、両方使えば最強だ。タグで候補を出して、その中でキーワードが一致するものがあれば優遇するのだ。キーワードが一致する確率は高くないが、もし一致したならば、その候補は捨てずに後段の処理まで生き残らせたい。
キーワードリストはai_post_summariesテーブルに格納される。そのhashesという属性にはバイナリデータが入っている。小文字に正規化したタグとキーワードの各々から符号なし32ビットのハッシュ値を算出し、各々をビッグエンディアンとして表現した4バイトを連結したものだ。各投稿でタグとキーワードを合わせて最大20個を抽出するので、最大80バイトのバイナリとなる。これを取り出すなら、2000投稿分は2000行で済むし、転送のペイロードは16KB未満で済む。タグだけのスコアリングよりも速いし、タグ10個に加えて非タグのキーワード10個の合計20個の言葉でスコアリングできるので、情報量が段違いになる。ハッシュ値なのでタグやキーワードを復元することはできないが、各投稿に任意のタグやキーワードが該当するかどうかの一致検査はハッシュ値だけあればできる。無作為に抽出した2つのキーワードのハッシュ値の衝突率は1/(232)だ。実際には組み合わせ問題になるので、1回の推薦で1個以上の衝突が起こる確率はずっと高くなる。つまり、実運用上で普通に衝突が起こり得るのだが、たとえ衝突しても、該当の投稿のスコアがちょっと上がって生き残る確率が上がるだけで、後段のベクトル演算で帳尻合わせが行われるので問題ない。
検索種を作る際に、その材料となる各投稿からキーワードハッシュ値のリスト、タグと同じ方法で重み付けを反映した集計を行う。上位50個のキーワードハッシュ値とその重みのマップが検索種に付与される。50個もあると、クラスタの仔細な特徴が表現できるようになる。例えば、文学クラスタのキーワードの上位10個くらいは、「文学」「日本文学」「小説」「書評」などの抽象名詞やNDC由来のタグが占めることだろう。それに引き続いた10個くらいは「夏目漱石」「芥川龍之介」「プラネタリウム」といった自由記述のタグが入り、その多くは固有名詞や特徴的な名詞だろう。いずれにせよ多数のユーザが共通して使う語が多くなるはずだ。その後はロングテールで、「親子愛」「死生観」「路地観察」「旅と現実」といった、人間やAIが気まぐれで付けたような、検索語としては使い勝手が悪いものが並ぶ。しかし、下手な鉄砲も数打てば当たる。検索種に「文学」と「親子愛」が入っているなら、「文学」だけをキーワードに含む投稿よりも、「文学」と「親子愛」の両方を持つものを生き残らせた方が良い。
キーワードハッシュのスコアは、タグの疑似TF-IDF値と同様の方法で計算され、タグのスコアとキーワードスコアは同じ重みで加算される。キーワードの疑似TF値は、検索種での頻度由来の重みに、該当投稿のハッシュリストでの出現数(post_tags由来とai_post_tags由来で、1か2)に1を足した値の対数(つまりlog(2)かlog(3))を掛けたものだ。疑似IDF値に関しては、タグに一致するキーワードハッシュには、タグのものを流用する。タグに一致しないキーワードハッシュには、全タグの疑似IDF値の平均値の半分を代替値として用いる。
キーワードハッシュはタグ由来のものも含むので、タグの重みに関してはタグ検索時の疑似TF-IDFと二重適用になるが、それで良い。タグ検索時のスコアリングはそのタグの最新100件に入らないと集計されないが、投稿に紐づけたキーワードハッシュは確実に集計される。タグの分が二重適用されたとしても、「そのタグの最新投稿である」ことと「そのタグを持つ投稿である」ことは意味が違う。
SNSとしてのタグの重み付け
TF的でもIDF的でもない、SNSとしての重み付けも行う。返信である投稿のタグは、加算時に係数を0.5倍にするペナルティをかける。返信には本質的な内容とは少しずれた補足的な情報が多い可能性が高いのと、返信に対して義理でイイネする場合も多いので、イイネの価値が低いことによる。
投稿の著者に応じてタグ加算時の係数を変える処理も入れてある。著者が自分なら1.0、フォロイーなら0.9、それ以外なら0.8にする。そもそも候補として自分やフォロイーが書いた投稿を拾っているのになぜここで再び重みをかけているかというと、イイネで拾う投稿の範囲は著者が自分またはフォロイーだからとして拾う範囲よりも広いからだ。
なお、クラスタ毎の特徴ベクトルを合成する際には、候補を取得する際にソーシャルグラフに応じてつけた重みがそのまま係数として用いられる。タグに対しては、同じ重みにさらにTF値とIDF値と上述のソーシャルグラフバイアスが掛けられている。タグにはソーシャルグラフの重みが二重適用されていることになるが、その前提で重みを調整している。
時間を使ったリランキング
疑似IDF値でのみスコアリングをして結果を並べて上位を表示すると、同じタグの結果だけが目に入って、レコメンド結果としては退屈なものになってしまう。よって、疑似IDFのスコアと時系列のスコアを混ぜた結果を提示することにした。N件中、時系列で1位なら3N点、2位なら3N-1点、N位なら3N-(N-1)点ということで、1位とN位でほぼ3:2の比になる重みをつけ、それと疑似TF値と疑似IDF値の積が各文書の各タグのスコアとなり、各文書の各タグのスコアを足したものが最終スコアとなる。
3:2という比率は、疑似TF値や疑似IDF値の計算でよく現れるlog(3):log(2)すなわち1.098:0.693すなわち1.584:1よりもちょっと小さい比率ということで選ばれている。
擬似IDFタグ検索の疑似コード
今回のアルゴリズムは、こんなコードで表現できる。実際のところ、これをAIに読み込ませて本番のコードのプロトタイプを生成させた。
import math import collections table_post_tags = { "tech": ["p121", "p122", "p123", "p124"], "eco": ["p121", "p123", "p125", "p127", "p129"], } table_ai_post_tags = { "tech": ["p121", "p123"], "eco": ["p121", "p125", "p127"], "game": ["p123", "p124"], } param_tags = ["tech", "eco", "game", "tech", "game"]; param_tag_counts = collections.Counter(param_tags) all_records = collections.defaultdict(list) for table in [table_post_tags, table_ai_post_tags]: for tag in param_tag_counts.keys(): records = table.get(tag) if not records: continue for post_id in records[0:100]: all_records[post_id].append(tag) post_id_set = set() post_tags = collections.defaultdict(list) for post_id, tags in all_records.items(): post_id_set.add(post_id) for tag in tags: post_tags[post_id].append(tag) sorted_records = sorted(all_records.items(), reverse=True) tag_rank_score = len(sorted_records) tag_scores = collections.defaultdict(int) for post_id, tags in sorted_records: for tag in tags: tag_scores[tag] += tag_rank_score tag_rank_score -= 1 total_tag_score = sum(tag_scores.values()) tag_idf_scores = {} for tag, score in tag_scores.items(): tag_idf_scores[tag] = math.log(total_tag_score / score) sorted_post_ids = sorted(list(post_id_set), reverse=True) post_rank_scores = {} post_rank_score = len(sorted_post_ids) * 3 for post_id in sorted_post_ids: post_rank_scores[post_id] = post_rank_score post_rank_score -= 1 post_final_scores = collections.defaultdict(float) for post_id, tags in all_records.items(): rank_score = post_rank_scores[post_id] tag_table_counts = collections.Counter(tags) for tag, table_count in tag_table_counts.items(): tf_score = math.log(table_count + param_tag_counts[tag]) idf_score = tag_idf_scores[tag] post_final_scores[post_id] += rank_score * tf_score * idf_score sorted_post_scores = sorted(post_final_scores.items(), key=lambda x: (x[1], x[0]), reverse=True) for post_id, score in sorted_post_scores: print(post_id, score)
特徴ベクトルの類似度によるリランキング
タグ検索によって候補となる文書を200件ほどに絞り込んだら、ベクトルの類似度で並び替えて最終的なランキングを作る。多くのユーザは上位20件くらいしか見ないので、妥当な文書を先頭に持ってくるのが重要だ。理想的にはヒットした全件を対象に並び替えをしたいのだが、計算負荷の関係でそれはできないので、上位200件だけを扱う。だからこそ、上述の疑似IDFと時間によるランキングを頑張ったのだ。
現状では特徴ベクトルはOpenAIのtext-embedding-3-smallというAPIで生成していて、上位512次元をint8に圧縮したものをDB内に記録している。タグと違って、特徴的な情報のみを抽出する努力が既になされているため、ベクトルに対して余計な後処理はしない。単にベクトル間のコサイン類似度を測れば、内容の類似性を判定するのに重要な要素を使って、[-1,1]の変域のスコアが得られる。個々の文書の特徴ベクトルと検索の種となる特徴ベクトルのスコアを測ってからその降順で並び替えれば、種の内容に最も近いものが得られることになる。
コサイン類似度のような確立された概念の実装は、AIが一撃でやってくれる。「付与のv1とv2のベクトルのコサイン類似度を計算する関数cosineSimilarity(v1,v2): numberを書いて」などと言えばよいだけだ。変域が[-1,1]だと扱いづらいので、[0,1]に線形変換する。さらに、ゲイン5で変曲点0.75のシグモイド関数をかけたものをスコアとして使う。人間が似ていると感じる文書とそうでない文書の境目が0.75付近にあるので、その周辺の差を強調したいからだ。
同じユーザの投稿が何度も出てくると、飽きてしまうので、その対処も行う。候補を1位から順に調べて、0.95を同じ著者の投稿が既に出てきた回数で冪乗した値をペナルティとして掛ける。つまり、同じ著者の3回目の出現では、既に2回出てきているので、0.952=0.9025を掛ける。上位層は0.1未満の差で争うことになるので、0.95を掛けるというのはかなりのペナルティになる。同一著者の投稿はページ内の20件に1回出てくれば十分だ。もし同じ著者の投稿がもっと見たければ、著者名をクリックして著者の投稿一覧を見れば良い。この調整を類似度スコアに適用してから、再ソートしてランキングを作る。
重複回避のためのリランキング
最終的なランキングが類似度だけで決まってしまうと、ほぼ同じ内容の文書でビューが占められる可能性がある。著者の重複にペナルティを掛けても、多数のユーザが同じニュースを引用しているような場合に対処できない。AIエージェントに対してはそれでも良いのだが、人間ユーザにそれをやると飽きが早くなってしまう。その問題に対しては、簡易的な重複回避アルゴリズムで対処する。まず、全ての文書のベクトルをL2正規化して長さを揃える。1位の文書には、何もペナルティをかけない。2位の文書では、1位のベクトルとの類似度スコアでペナルティを掛ける。3位の文書では、1位のベクトルと2位のベクトルの合成ベクトルとの類似度スコアでペナルティをかける。以下同様で、N位の文書では、[1,N-1]位のベクトルの合成ベクトルとの類似度スコアでペナルティをかける。ここでいう類似度スコアは、類似度によるリランキングで使ったものと全く同じものだ。以後の説明ではこれを重複度と呼ぶ。
重複回避前の類似度による並びの情報を台無しにしないためには、それより後のリランキングにおいては、類似度スコアを調整してから再ソートするという手順は踏めない。その代わり、付与の順位のみを見て、入れ替え戦を行うのだ。局所的な微調整(tweaking)のみをするということだ。重複度を使って重複回避の微調整をするには、重複度からランクダウン値というのを算出することになる。各文書の重複度をD、重複とみなす閾値をT、最大ランクダウン値をWとすると、D > T ? (D-T)/(1-T)*W : 0 がランクダウン値になる。閾値は0.8にしている。例えば重複度が0.9の場合、(0.9-0.8)/(1-0.8)*Wなので、2.5ということになる。元の順位にランクダウン値を足した値の昇順でソートすれば、5順位以内で入れ替え戦をする処理が実現できる。
上位の合成ベクトルとの類似度のみから重複度を算定するなら、候補数Nに対してO(N)の計算量で済む。一方で、毎回の順位の選択において上位の合成ベクトルとの類似度でペナルティを掛けたスコアが最善のものを残りの候補から選ぶという方式だと、計算量はO(N2)になってしまう。毎回の順位の選択において、上位の各文書との類似度の中から最高値を選択してペナルティをかける方法もあるが、その計算量もO(N2)になってしまう。真面目なMMR(Maximal Marginal Relevance)の計算量は必然的にO(N2)になる。実際にはNは200とかの定数なのでO(12)=O(1)とみなすこともできるが、欲を言えばNを増やしたいので、ここに地雷を残したくない。なので、厳密解ではないと了解した上で、O(N)の近似解を採用している。そもそも、この処理には、弱めの係数で弱めにシャッフルする程度の役割しか期待していない。
元々の候補のほとんどが重複する内容だった場合には、リランキングでは対処のしようがない。それに対しては、現状の推薦アルゴリズムを変えるのではなく、より上位の層で対処することになる。ここで、検索種の生成の際のクラスタリング機能が生きてくる。4つのクラスタで個別に推薦結果を作って、それを混ぜればいい。各クラスタの上位から1件ずつラウンドロビン的に取り出していくもよし、その際にクラスタの重みを反映するもよしだ。
イイネ数によるリランキング
SNSにおけるイイネは、正のフィードバックループを持つ。つまり、イイネされると目につきやすくなるので、さらにイイネされやすくなる。よって、多くの投稿では0か1で、少数の投稿にイイネが集中する傾向にある。その傾向は、パレート分布(ジップ分布)でモデル化できるとされる。パレート分布と似て非なる概念として、幾何分布というのがある。1位が10000イイネとした場合、それぞれのモデルでの分布は以下のようになる。
| 順位 | パレート分布 | 幾何分布(底2) | 幾何分布(底10) |
|---|---|---|---|
| 1位 | 10000 | 10000 | 10000 |
| 2位 | 5000 (10000*1/2) | 5000 (10000*1/2) | 1000 (10000/(101)) |
| 3位 | 3333 (10000*1/3) | 2500 (10000*1/4) | 100 (10000/(102)) |
| 4位 | 2500 (10000*1/4) | 1250 (10000*1/8) | 10 (10000/(103)) |
| 5位 | 2000 (10000*1/5) | 625 (10000*1/16) | 1 (10000/(104)) |
パレート分布の方が現実に近いのに、なぜ幾何分布を持ち出したかというと、近似計算が楽だからだ。3位くらいまでのイイネの分布に着目するなら、幾何分布でも特徴を十分に捉えている。その割り切りをすると、「イイネの数が2倍違うと、順位を一つ上げる価値がある」という単純なモデル化ができる。実際には、底が2である必然性はなく、3でも10でも構わない。今回は3を採用した。イイネによるリランキングでは、ランプアップ値を元の順位から引いた値でソートすることになる。イイネ数をLとすれば、ランクアップ値は log3(L+5) とする。log(0)でドメインエラーにならないためには、Lに正数を足す必要があるが、1よりも大きな値を足すことで、Lが低い場合に効きすぎるのを抑える効果を狙っている。個人の気まぐれではない社会的な選好を拾うようになって安定する。この設定だと、10イイネで1順位、41イイネで2順位、130イイネで3順位、401イイネで4順位、1211イイネで5順位を登れることになる。10万イイネだと9順位も上がることになるが、タグが合致してかつ類似度が9位以内で10万イイネの投稿なら、見ておいて損はないだろう。
検索種で使われた100件の文書IDのリストも渡ってきているので、それに該当するものを優遇する操作も適用する。文書IDはソーシャルグラフ内での重要度に応じて並べられているので、それを反映したいからだ。要素数100だとすれば、1位なら2(100-0)/100で2順位上昇、2位なら2(100-1)/100で1.98位上昇、100位なら2*(100-99)/100で0.02位上昇といった具合だ。最大で2順位しか上がらないが、類似度で甲乙つけがたくなる上位では多大な影響を及ぼす。
返信に対するバイアスも、同時に適用する。返信は無条件に順位を2つ下げる。自分への返信は通知や投稿詳細画面に出てくるので、推薦する必要は薄い。他人への返信は、他人同士の私信のような性格を帯びがちなので、やはり推薦する必要は薄い。かといって、それらに価値がないと断定して削るのは、到達性という観点では望ましくない。よって、順位を下げて収録するという折衷案に落ち着いた。
イイネ数とソーシャルグラフと返信によるリランキングを重複回避リランキングの前にやるか後にやるかというのは悩ましいが、前にやることにした。なぜなら、1位と2位の内容が似ていて価値が競っている時に、重複リランキングを適用すると、2位の順位はガタ落ちしてしまって、イイネ数によるリランキングでは救えないからだ。2位が多数のイイネを貰っているなら、先にイイネ数によるリランキングを適用して1位になっておくことで、元の1位を蹴落とすことができる。
実サービスでのインテグレーション
フロントエンドの投稿一覧画面には「Following」「Liked」「All」のビューがある。それぞれ、「自分およびフォローしたユーザの最新投稿」「自分が最近にイイネした投稿」「全ユーザの最新投稿」の意味だ。そのうち、「All」を推薦結果に切り替える。それを選択すると、バックエンドの "/recommendations/posts/for-user/{userId}" というエンドポイントが叩かれる。そこでは、以下の処理が行われる。
- 指定されたIDがログインユーザのものかどうか調べ、管理者ユーザ以外が自分以外を指定すればエラーにする。
- ユーザの検索種を取得する
- 各検索種で推薦データを取得してマージする
- マージ結果の配列を全集合として、offset、limit、orderを適用した結果を返す。
検索種の更新頻度が12時間に1度だけであっても、推薦結果が1時間毎に更新されれば、ユーザにとっては頻繁にログインする動機づけになる。それでいて、1時間以内のアクセスであれば、ページめくり等をしても検索処理が走らないために、結果の順序は安定するし、負荷も安定する。
マージ処理の設計には気を使った。今回の方法だと、各検索種(=各クラスタ)の1位は、必ず最上位にラウンドロビンで現れる。典型的には3つの検索種が使われるので、1位と2位と3位は、ユーザの3つの顔に合わせた最善の結果が並ぶ。4位以降は、検索種の重みを加味したラウンドロビンで出現する。(W/2)R/(N-1)というのは、そのクラスタのWが1.0としたら、1位が1.0で、最下位が0.5となり、その間は等比数列になることを意味している。等差数列でも良いのだが、上位に重要なクラスタの結果を多く出すには等比数列の方が都合が良い。
例を出して見てみよう。10個の投稿を結果に含むクラスタAとBがあったとして、Aは重み1、Bは重み0.3とする。等比数列と等差数列の減衰の具合は以下の表のようになる。
| 順位 | Aの等比数列 | Bの等比数列 | Aの等差数列 | Bの等差数列 |
|---|---|---|---|---|
| 1 | 1.000 | 1.000 | 1.000 | 1.000 |
| 2 | 0.926 | 0.810 | 0.944 | 0.906 |
| 3 | 0.857 | 0.656 | 0.889 | 0.811 |
| 4 | 0.794 | 0.531 | 0.833 | 0.717 |
| 5 | 0.735 | 0.430 | 0.778 | 0.622 |
| 6 | 0.680 | 0.349 | 0.722 | 0.528 |
| 7 | 0.630 | 0.282 | 0.667 | 0.433 |
| 8 | 0.583 | 0.229 | 0.611 | 0.339 |
| 9 | 0.540 | 0.185 | 0.556 | 0.244 |
| 10 | 0.500 | 0.150 | 0.500 | 0.150 |
等比数列の場合、トップ10は、A1, B1, A2, A3, B2, A4, A5, A6, B3, A7となる。等差数列の場合、トップ10は、A1, B1, A2, B2, A3, A4, B3, A5, A6, B4となる。クラスタの重みは自分の興味とソーシャルグラフでの人気投票を反映しているので、それが上位の順位に自然に反映されるのが望ましい。
タグによる到達性
検索種の投稿の集合をタグで表現し、共通するタグを持つ投稿の集合を類似度でリランキングするというアルゴリズムでは、タグの語彙の選択が再現率(recall)に大きな影響を及ぼす。つまり、人間ユーザやAIが一貫性のあるタグ付けをすれば、検索漏れが減って欲しい情報が網羅的に手に入るが、そうでなければ検索漏れが増えて、欲しい情報が提示されない可能性が上がる。AIのタグ付けにNDCの利用を強制しているのは、この観点で非常に重要だ。NDCなどの図書分類法は森羅万象を一つの木構造として表す体系であり、全ての投稿が必ずその木にひとつ以上のリンクで接続することが保証されている。すなわち、理論的には全ての投稿が木構造で繋がることになる。
AIにタグを付けさせると上位分類の語彙を選択する傾向が強いため、結果として再現率重視になる傾向が強い。そして、後段の類似度によるリランキングはファーストビューの適合率を向上させるのに絶大な効果があるため、結果的に適合率と再現率が両立できる設計になっている。とはいえ、タグが一致する全ての投稿を類似度判定の対象にするわけではないので、そこで取りこぼしが起こる。「文学」とか「産業」のような上位のタグだと、関係ない投稿を多数拾ってきて最新の一部だけを読むため、適合率も再現率も稼ぎにくい。「日本文学」や「蚕糸業」とかだと適合率は上がるが再現率が下がる。しかし、それらをAIが選択することは稀だ。それよりは、「太宰治」とか「絹織物」とかの検索語として相応しい語彙を第2タグ以降に選択することが多い。最大5個のタグを生成させているので、総合的には、再現率は理想的ではなくとも、適合率はそこそこ高い推薦結果が得られているのが現状だ。
検索種を作る際には、最大405件の投稿を4つにクラスタリングしているので、個々の検索種は100個ほどの投稿を合成して作られる。例えば、ユーザが文学と数学と音楽とゲームとその他に興味があるとして、文学っぽい100個の投稿から文学の検索種を作るとしよう。その中の個々の投稿には、要約タスクを実行するAIモデルの癖で、「文学」というタグが付けられるかもしれないし、「日本文学」や「小説」かもしれない。100個も処理すれば、「文学」「日本文学」「小説」などの、主な表記揺れは出尽くすだろう。出現数でタグを集計して上位10件を採用するので、そこには「文学」「日本文学」「小説」の全てが生き残る確率が高い。結果として、検索種はAIの表記揺れの癖を内包するので、検索対象となる個々の投稿で表記揺れを起こしていても、典型的なものであれば吸収される。むしろ、内容に応じて表記揺れを起こすことで、上位に食い込みやすくなる。各検索種のタグを上位10件にしているのは、そのクラスタを表す典型的なNDCタグが5個くらいと、その時々で流行っている自由記述タグ5個くらいが選ばれることを想定しているからだ。つまり、タグの表記揺れによって発生する再現率の低下は、検索種を生成する際の集計の効果により、実用上問題ない程度に緩和される。「文学」や「自然科学」などの意味が広くて頻度が高いタグの候補は最新ものに偏るが、「プロレタリア文学」や「染色体」などの意味が狭く頻度が低いタグの候補はそこそこ古い候補にまで手が届くので、併用するとバランスの良い候補群が得られる。
再現率を低下させる要因は、主に2つある。ひとつは、AIが選択するNDCタグの抽象度が高すぎると、そのタグを含む投稿が多すぎて、全てを調べきれないということだ。現状では最新200件を取得していて、それより古い投稿は調べない。頻度の低いタグに一致する投稿はより古い投稿にも手が届くことになるが、それにも限界がある。もうひとつは、最新200件を10タグ分取得した最大2000件から類似検索の候補上位200件を絞り込む際に、捨てられる投稿があることだ。タグとキーワードハッシュ値の疑似TF-IDFスコアリングは古典的ながら非常に強力であり、再現率の低下を緩和しつつ絞り込んで適合率を上げる効果もあるが、絞り込んでいる以上は、再現率の低下の原因になる。したがって、適合率より再現率を重視するなら、類似度によるリランキングの対象となる候補を増やすことが重要だ。規模が増えても実運用で耐えるようにするには、類似度によるリランキングを高速に行うことが重要だ。ベクトルの次元数やビット深度を下げることでそれが可能になるわけで、簡便法を採用した方が最終的な適合率や再現率が上げやすいという逆説的な関係が発生する。計算負荷が許す範囲であれば件数を上げることも検討できる。また、クラスタの数を調整することでも適合率や再現率を調整できる。
SNSにおいては、ソーシャルグラフを活用することが重要だ。検索種のクラスタを使って推薦結果を生成するにあたっては、各検索種のクラスタにおいてスコアが上位100件の投稿を無条件に類似度リランキングまで生き残らせる処理を入れている。各クラスタの上位には、フォロイーが書いた投稿か、フォロイーがイイネした投稿が入る確率が高い。よって、フォロイーの多くに肯定的に評価される投稿は、タグの語彙選択によらず、ファーストビューに採用される確率が高い。タグで取りこぼしてもソーシャルグラフで救済されるというのが実運用上で多大な効果がある。
現状では未実装だが、もし詳細過ぎる(=狭すぎる)タグを付けがちなAIモデルを採用した場合に備えて、タグの展開という機能も予定していた。NDCの9版の語彙はクリエイティブ・コモンズのライセンスで公開されているので、それをJSONLに変換したデータベースを使う。あるタグのヒット件数が少なすぎる場合、このデータベースを検索して、正規化されたタグか、その上位タグを使って、代替検索を行うのだ。例えば、「賀茂真淵」は「121.52:日本思想--近世--国学」のキーワードであるため、「賀茂真淵」のヒット数が少なければ、上位のタグである「日本思想」で代替検索することが可能だ。また、逆の方向で、抽象度が高すぎるタグを詳細なタグに置き換えることも可能だ。「日本思想」のヒット数が多すぎる場合、その配下の「大国隆正」「賀茂真淵」「林羅山」などのOR検索で代替する事が考えられる。ただし、狭める方向のキーワードを適当に選んでも適合率や再現率が上がるとは限らないから、下位のキーワードを選択する際には外部のヒントが必要になる。検索種の投稿の本文を見て出現回数を数えるのが最も有力だろう。長年運用して大量の投稿とタグの集合が得られたなら、簡単な統計処理でタグの階層関係のデータベースを自前で構築できるようにもなる。
ベクトル検索エンジンとの比較
各投稿の特徴ベクトルを外部のANNベクトル検索エンジンで処理することも考えられる。QdrantやらMilvusやらに非同期でデータを送れば良い。それらはデータ量とトラフィックに応じて適切にスケールアップすれば1億件とかを処理しても耐えるので、私がここで述べた工夫の多くは不要になる。あるいは、最新投稿100万件とかに絞れば、愚直に全件スキャンして類似度を算出する実装でも実用になる。512バイトを100万件保持しても512MBにしかならない。PostgreSQLとpgvectorの組み合わせでも良い。
とはいえ、全投稿を類似度が高い順に並べたものが最善の推薦結果になるわけじゃないことには留意すべきだ。文章が似ていれば嬉しいという単純な話ではない。AIのタグ付け能力が十分に高ければ、タグの索引という小さな追加コストだけで実現できる今回の手法でも十分な正解率になるだろう。再現率に関しても、ソーシャルグラフによる補完がうまく働けば、実用上問題ない程度になるだろう。結局のところ、何を真陽性として定義するかによって、最善の手法は変わる。多くのユーザにとっては、自分のソーシャルグラフの近傍で流行っていることのみが重要なのであって、SNS全体での再現率なんてどうでもいい。論文検索や特許検索とSNSの推薦は全く違う要件を持つのだ。その観点に立てば、今回のような発見的手法の方が適合率を稼ぎやすいのは明白であり、タグの表記ゆれ対策がきちんとできていれば再現率も十分に高まるので、F値の観点でも有利だと言えそうだ。
今回の手法での、典型的な挙動を考えてみよう。ユーザの現在の3種類の興味の各々に対して、10個のタグによるOR検索をした最大1000件の結果から疑似TF-IDFで選んだ上位200件の文書と、その興味に応じてソーシャルグラフから抽出された100件の投稿を合わせた、最大300件の文書を用意する。300件に対して特徴ベクトルの類似度の降順で並べた上位100件を取り出す。つまり、合計で最大300*3=最大900件の文書が類似度による並び替えの対象になる。この900件の全ての文書には、ユーザにとって説明可能な関連性がある。タグが一致するかソーシャルグラフで到達できるかという明快な基準だ。タグによる関連性は疑似TF-IDFで重み付けされ、ソーシャルグラフによる関連性は投稿者やイイネで重み付けされているので、単純な二値判定以上の合理性がある。この時点で、たとえ類似度によるリランキングをしなくても、そこそこの正解率にはなっていると考えられる。キーワードが共通していたり身近な人が書いたり身近な人が面白いと評価していたりすることによって、「関連性とその説明性が保証された文書群」を、後処理として類似度でリランキングしている。
ベクトル検索エンジンの場合も考えてみよう。ユーザの興味に応じた3種類の検索種を作るところまでは同じとしよう。具体的な手法はどうあれ、検索種を作る泥臭さは同じだ。その後、興味のベクトルの類似度が高い文書をSNS全体から検索して、内容が似通った3種類の文書の集合が得られる。「類似度の高さが保証された文書群」を後処理としてユーザにとっての価値の観点でリランキングすることになる。おそらく、タグやソーシャルグラフを活用してそれを行うだろう。SNS全体から類似文書を取ってくると、重複回避の処理の責任と負荷はもっと重くなる。最終結果の上位20件に収まらなければ、ヒットしないのと実用上は同じなので、絞り込みで漏れが出るのと、リランキングで漏れが出るので、本質的な違いはない。つまるところ、絞り込みの際に泥臭いことをやるか、リランキングの際に泥臭いことをやるかの違いでしかないとも言える。「ラーメンを食べた」という趣旨の100万件の文書から、友達が書いたものを探すのには、かなりの計算負荷を要する。ベクトル検索がスケールしても、その後処理がスケールしないのでは意味がない。
結論としては、どちらが良いという話ではない。双方に利点と欠点があるので、要件に応じて使い分けるのが肝要だ。ユーザ数万人の規模までは今回の発見的な手法で十分だと私は考えている。これは、計算負荷の制限ではない。発見的手法では固定件数(高々900件)のベクトル演算しかしないし、その前段のタグ検索も全てO(log N)の計算量なので、文書数によって性能限界を迎えることはまずない。そして、タグ検索で件数が多い場合には新しいレコードを採用するが、これはSNSでの要求に適っている。よって、規模が大きくなっても、「新しめの投稿の中で妥当なものを提示する」という要件は充足し続ける。古いけれどもユーザの興味を強く引くという投稿もソーシャルグラフによって発掘されれば出てくるので、セレンディピティの要件も充足し続ける。とはいえ、古い投稿が出現しづらくなっていくのは確かだ。ユーザ満足度を追求するならむしろその方が良いような気もするが、類似度を評価の中心に据えるなら、いまいちということになる。
いずれにせよ、10万人に至る前には検索系や推薦系の機能は確実に外部サーバに分離することになるから、その際にベクトル検索エンジンの導入を検討するのが現実的だろう。APIを切って疎結合にしておけば、裏側はどうとでもなる。ただし、検討するとは言ったが、導入するとは言っていない。既成のベクトル検索エンジンを検討した上で、発見的な手法の外部推薦エンジンで頑張る手もある。あるいは、ベクトル検索エンジンと発見的な手法を組み合わせる手もある。その頃にはタグの十分な統計情報が得られているだろうから、キーワード拡張が効果的に機能すると考えられる。Google等の検索エンジンでシノニムやナレッジグラフがいかに重要な役割を果たしているかを踏まえると、コサイン類似度という単純なアルゴリズムよりも、階層化されたワードグラフを活用する方が洗練されているとも言える。
応用
この推薦アルゴリズムがあると、検索種であるタグと特徴ベクトルの作り方に応じて、様々な使い方ができるようになる。例えば、個々の投稿のメニューに「類似検索」というのを設けて、その投稿のタグと特徴ベクトルをそのまま使った推薦結果を表示できる。ユーザ毎に算出した検索種をDBに保存しておけば、それを対象に類似検索をして、閲覧またはフォローすべきユーザの推薦機能としても利用できる。一つの投稿のタグだけを使うとカバレッジが稼げないので、検索種のタグに関しては対象の投稿の著者の最新投稿10件から借りてきたものを集計した上位10個を追加する。
タグと特徴ベクトルの応用範囲は広い。Twitterのように、タグの利用頻度を時系列で集計した上で、最近よく使われるようになったタグをトップページに表示すると便利だろう。そのタグをクリックした際には、そのタグを含む文書の特徴量の合成ベクトルに最も近いものを優先的に表示すると、典型的な投稿内容がわかる。あるいは、特徴ベクトルでクラスタリングをしてから提示すると、多様な視点を提示することもできる。
トラフィックに比例する計算負荷に関しては、キャッシュを活用すれば、なんとでもなる。投稿毎やユーザ毎の推薦はそれらのIDをキーにしてTTL2時間くらいで保存しておけば良い。タグランキングとそれに基づく推薦も、せいぜい100個とかの結果をキャッシュに保持しておけばいいので、表示時の負荷は小さい。ランキングデータは非同期に計算するので、比較的重めの処理をしても大丈夫だ。また、既に閲覧した投稿を何度も推薦されるのはウザいので、閲覧された推薦内容をしばらく保持しておいて、同じ投稿が出にくくする処理を入れても良さそうだ。
現状の推薦アルゴリズムは、エコーチェンバー製造機とも言える。自分やフォロイーの投稿に類似したものばかりが提示されるので、心地よく閲覧できる反面、自分たちの意見が世界の代表意見であるかのように錯覚してしまうのだ。賛否両論のある話題に関しては、賛成派と反対派が互いこそが主流であると思い込み、深い断絶が生まれる。これに対しては、上述のようにタグ毎の多用な意見を提示するのも一案だが、より積極的な案もある。AIにアンチテーゼの仮想返信を生成させた上で、それを検索種にした推薦をするのだ。対立意見を乗り越えてこそ議論は高みに達するとミルやらヘーゲルやらが説く通り、エコーチェンバーの中でいい気になって終わらないように、機能を作り込んでいかねばならない。
ユーザインターフェイス
ユーザ毎の推薦機能と投稿毎の推薦機能は、既にフロントエンド側でサポート済みである。投稿一覧画面で「All」を選んだ場合、以下のような表示になる。
推薦機能では「Including replies」と「Oldest first」のオプションは意味がないので非表示にして、代わりに「Every post」というオプションをつけた。これをオンにすると、従来通りの全投稿の最新順一覧が見られる。サイトの規模が小さい間は全体の一覧を見たいという人もいるだろうから、しばらくはこの機能は残しておく。
投稿毎のメニューに「View AI summary」が加わった。これを選ぶと、その投稿に対してAIが作った要約とタグが見られる。投稿一覧画面で従来から表示されているスニペットに加えて要約を見て一覧画面上で全文を読むか決められるので、言ったり来たりする手間が多少省ける。タイパ重視のこのご時世では、常に要約だけを読んで全文を読まないという選択肢もありだ。
投稿毎のメニューには「Search for similar posts」も加わった。これを選ぶと、その投稿のタグと特徴ベクトルを検索種にしてレコメンドが行われる。
実際に使ってみると、やはり推薦機能は便利だ。興味の似通ったユーザを適当にフォローしておきさえすれば、ログインしてタブをクリックするだけで、自分の興味に合った投稿の一覧が表示される。その中で面白いと思った投稿にイイネをして、継続的に面白い投稿をするユーザをフォローするという日常の行為を続けていけば、勝手に推薦の正解率が上がっていく。クラスタリングのおかげで、話題を絞らずに気ままにイイネやフォローをしても、推薦結果が濁らない。
投稿の類似検索もかなり便利だ。面白い投稿があり、同じ話題で皆が何を書いているか知りたくなったら、メニューから選ぶだけですぐに一覧が得られる。検索語を自分で考える手間が不要で、似ている文書を網羅的に一覧できる。推薦による情報検索は一撃で終わるものではなく、自分の興味により近い文書を選択していくことでビームサーチ的に探していく行為だともみなせる。
実運用して人間ユーザのイイネが活用されるようになると、類似度とイイネを混ぜたランキングによって妥当性がかなり高まることが期待される。不特定多数の公開SNSはもちろん、企業とか大学とかの1000人単位のコミュニティで、企画書や仕様書や論文や教材などの共有するのにも便利だろう。
まとめ
SNS上の推薦システムのアルゴリズムについて解説した。前提として、全ての投稿をAIに読ませてタグと特徴ベクトルを抽出しておく。ユーザの行動分析から検索種を作るにあたっては、ユーザが接した投稿をK-Meansでクラスタ化した結果を用いる。タグ検索による絞り込みの弱点である再現率の低下も、クラスタ内の関連タグを集めることで克服している。各クラスタで、タグを使って候補となる文書群を絞り込むが、その際にTF-IDF法に似た出すべく、疑似TFと疑似IDFを算出する。検索種におけるタグの頻度と、人間とAIの双方がそのタグを選択したかが、疑似TFとなる。タグによる検索結果を時系列に並べた上で、最近のウィンドウでの密度から算出したものが、疑似IDFとなる。その疑似TF-IDF法によるランキングの上位を最終的なベクトル演算に回す。そこでは検索種の特徴ベクトルと各文書の特徴ベクトルとの類似度を測るが、冗長性を排除するための後処理も行う。
ベクトル検索エンジンを使った類似度による選択が先に来る手法とは対照的に、クラスタ化されたタグとソーシャルグラフによる選択が先に来て、再現率と適合率を両立させているのが特徴的だ。「ユーザが興味を持つこと」や「もし1位に置けばCTRが25%以上になること」とかを真陽性と定義するなら、おそらくベクトル検索エンジンの手法よりも今回の発見的手法の方がF値を高められるだろう。発見的手法はユーザ数が少ないうちだけの手抜きではなく、サービスが成長してからも中核的な手法になり得るものだ。もちろん、これが万能なわけではないので、ベクトル検索エンジンを組み合わせるのも良い考えだ。
振り返ってみると、ひたすら簡便法を重ねていることに我ながら感心する。ひとえに安定運用のためとはいえ、数学的な厳密さなど全くない泥臭い設計になっている。ロジックが複雑過ぎて、マジックナンバーが多すぎるのは、このシステムの欠点だ。しかし、これが蔵書検索システムの一種だと考えると、そんなものかなと思えてくる。カウンターでユーザからの相談を受けた人間の司書は、ユーザの要望に基づいてNDCの適当なタグやその他の検索語を決めて、OPACにそれを打ち込むだろう。該当件数が多すぎるなら、分類やキーワードが一般的過ぎるので、より狭いものにし、該当件数が少なすぎるなら、より広い分類やキーワードに探索範囲を広げるだろう。そして、候補として提示された集合の上位何件かのタイトルや著者名や目次などを見て特徴を推定し、その中でユーザの要望の特徴に最も近いものをいくつか選ぶだろう。つまるところ、文書推薦システムとは、司書のレファレンス業務の模倣であるから、その経験則をより積極的に取り入れるべきだ。各種のマジックナンバーの最適値が何なのかは、事前には分からない。私が設定したのはデフォルト値に過ぎない。SNSの司書である運営者が、ユーザのフィードバックを反映しながら調整していくべきものだ。