FakebookというSNSのシステムを最初から最後まで作り上げる過程について連載する。必要十分なSNSシステムとしての機能を備えつつ、AIユーザが勝手に議論を進めるプラットフォームに仕上げる予定だ。初回は目標と概要設計とアーキテクチャについて述べる。
 |  |
背景と目標
ITエンジニアが一人で案件を回せるようになるためには、いわゆるフルスタックエンジニアと呼ばれるようなスキルセットを身につける必要がある。今時だと、その中には以下のようなスキルが含まれるだろう。
- ユーザの要求をまとめて、それを満たす概要設計を行う。
- アーキテクチャを決め、開発や運用に必要な既存システムを選定する。
- 開発環境(ローカル環境)や運用環境(クラウド・オンプレ)の整備をする。
- Webサーバ、DBサーバ、ストレージサーバ、認証サーバ、メールサーバ等の設定をする。
- UXデザイナとして、ユーザが触れる画面の見た目や機能を設計する。
- フロントエンドエンジニアとして、上記の仕様を満たす機能を実装する。
- バックエンドエンジニアとして、フロントエンドから呼ばれるサービスとそのAPIを実装する。
- 結合テスト、システムテスト、運用テスト等々を行う。
- 全工程をリストにまとめて可視化して、スケジュールを立て、開発を進める。
私の現状のスキルセットは、いわゆるバックエンドエンジニアとしてのスキルに偏っているので、ここらで自らのフルスタック化を図りたい。また、AI時代に対応すべく、可能な限り多くの工程でAIを使って効率化を図りたい。その練習として、何か実際に動くシステムを作ってみようと思った。
考えた末、シンプルなSNSを作ることにした。SNSには、典型的なビシネスシステムの要件が詰まっているからだ。多数のユーザがいて、そのアカウントを管理し、各ユーザの認証と認可をする。ユーザから預かったデータは、適切なスキーマを定義した上でRDBMSに入れて管理する。画像などはストレージサーバで管理する。ユーザ登録やその他の通知はメールサーバで処理する。そして、フロントエンド・バックエンド・DB/ストレージの典型的な三層構造のアーキテクチャにそれぞれのサブシステムを収める。
蛇足。「フルスタック」と言うからには、DBMSやオブジェクトストレージやWebサーバやコンテナ技術などのインフラ層のスタックも実装できて、もっと言えばクラウド基盤やらOSやらハードウェアやらのスタックも実装できるべきだという話もあるが、現実的にはそんな超人は存在しない。仮に存在したとしても、限られた労働時間の中でその才覚の全てを発揮する機会はないだろう。巷で言うフルスタックエンジニアというのは、いわゆるSI案件のプロジェクトで重宝されるスキルセットの多くを備えている技術者という程度の意味しかない。それでフルスタックなどと言うのはおこがましいので、私もフルスタックエンジニアを自称することは一生ないと思うが、重宝される≒稼げる≒生き残れる、エンジニアになりたいとは思っている。
概要仕様
Fakebookは、Twitter的なミニブログ形式のSNSである。SNSとしての特徴を以下に挙げる。
- 短文と長文の両立:記事はMarkdown形式で長々と書けるが、一覧には抜粋のみが表示され、多くの記事を閲覧しやすくなっている。
- 返信による木構造:各記事は任意の記事への返信として書ける。返信記事にも返信ができるので、コミュニケーションは木構造になる。
- 単方向フォロー:他のユーザを一方的にフォローできる。フォローバックをするかしないかは自由。
- Like:任意の記事をLikeできる。
- 記事の一覧モード:フォローしたユーザの投稿一覧、Likeした投稿一覧、全ての記事一覧を切り替えて投稿を切り替える。
- 記事の詳細表示:特定の記事の本文全文と、その記事に対する返信記事の概要一覧が、同時に見られる。
- ユーザの一覧モード:自分がフォローしたユーザ一覧、自分をフォローしたユーザ一覧、全てのユーザ一覧を切り替える。
- ユーザの詳細表示:特定のユーザのプロフィールと、フォロー関係のユーザの一覧が、同時に見られる。
- 検索:著者名、本文、タグを条件とする投稿の検索ができる。名前や自己紹介を条件とするユーザの検索ができる。
- ユーザ登録:メアドに確認メールが届くなら、誰でもユーザ登録できる。
Fakebookという名前がFacebookのパロディなのは言うまでもないが、フェイクのユーザが存在するという含意がある。すなわち、ユーザアカウントに紐づけたAIに閲覧操作や投稿操作を行わせて、勝手に賑わったSNSを作ってくれるということだ。この辺の詳細は全然詰められていないのだけれど、おそらく以下のような機能になるだろう。
- 各アカウントにAIモデルとパーソナリティが紐づけられる。
- 定期的にAIアカウントが起こされ、そのAIアカウントは一連の行為を行う。
- 閲覧行為:自分のフォロー関係にある記事を閲覧し、フォロー外の記事もランダムに閲覧する。
- 投稿行為:閲覧内容とパーソナリティを鑑みて、適当な記事を書く。
- 返信行為:閲覧内容とパーソナリティを鑑みて、興味のある記事をいくつか選択し、返信を書く。
- Like行為:閲覧内容とパーソナリティを鑑みて、興味のある記事をいくつか選択し、Likeをつける。
- フォロー行為:閲覧内容とパーソナリティを鑑みて、興味のあるユーザをフォローに加え、興味のないものは外す。
- 事前に予算を決めておいて、AIの活動頻度のペース設定を行う。
この機能を導入するのは、今後のAI時代のシステム構築の練習という意味で最適だ。ステートレスAPIを使って記憶を擬似的に再現するために閲覧行為があり、それによって動的に作成されたプロンプトを動かすことになる。そして、特定の行為や行為対象を選択するという定型操作をするとともに、記事の内容を生成するという非定型的な操作も行う。それを、適切なペースで動かし、コスパの調整をする。必要であれば、ダッシュボードなどの管理機能も作ることになるだろう。
アーキテクチャ
アーキテクチャは、多くの案件で使い回せるような典型的なものにしたい。よって、以下の図のような構成にした。

具体的な設計を進めるにあたり、まず最下層のサブシステムの選定を行った。この段階からいきなりAIを使った。ChatGPTに、以下のように語りかけるだけだ。
シンプルなSNSを作りたいのだが、オンプレでもクラウドでも動くようにしたい。 フロントエンド、バックエンド、ストレージ層の3層アーキテクチャにする。 ユーザやコンテンツのデータの管理にはRDBMSサーバを使う。 画像やその他のメディアデータはストレージサーバに格納する。 セッション管理やその他の一時データにはキャッシュサーバを使う。 ユーザ登録等でメールサーバを使ってメールを送信する。 フロントエンドとバックエンドはTypeScriptだけで書きたい。 この要件で、利用する技術の選定を行って。
そうすると、なんか長々と語ってくるので、知らない用語があれば聞き返すなどして、何度か質疑応答をする。最後に、自分が理解した内容を簡単にまとめて、合意形成を図るのが大事だ。
つまり、以下の構成でよい? - フロントエンドはNode.js+Next.js(React)で書く。 - バックエンドなNode.js+Expressで書く。 - DBサーバはPostgreSQL。クラウド上ではマネージドサービス(RDS等)を使う。 - ストレージサーバはMinIO。クラウド上ではマネージドサービス(S3等)を使う。 - キャッシュサーバはRedis。クラウド上ではマネージドサービス(ElastiCache等)を使う。 - メールサーバはPostfix。クラウド上ではマネージドサービス(Simple Email Service等)を使う。
そうすると、おそらく「完璧です!」的なおべんちゃらを言ってくる。その後、「じゃあ、フロントエンドの詳細を詰めていきますよ」などと言って会話を進めていけば良い。
最小構成
AWS上で運用するとして、全部一台のEC2に置く最小構成を考えてみる。EC2のt4g.small(2コアCPU、2GBメモリ)で7ドル、ストレージのEBS 8GBで1ドル、データ転送量10GB想定で1ドル、S3に32GBくらいデータを置くとして1ドルとして、パブリックサブドメインのNATなしで運用するとすれば、月額10ドルくらいで運用できる。アクティブユーザ数が1000人程度の内輪で使うSNSとして運用するなら、それで十分だろう。
アクティブユーザ数が1万人以下の中規模サイトまでなら、VPSでも十分運用できるし、その方がコスパが良い。例えば、さくらVPSの4GBプラン(4コアCPU、4GBメモリ、SSD 200GB)であれば、月額3227円で、初期費用4400円足せばSSDを400GBに拡張できる。PostgreSQLやMinIOやその他全てのサービスを同一ホストで動かしても1台で問題なく動く。EC2のt4g.smallよりはずっと高性能で、ストレージもずっと大きいので、安心して運用できる。何より、固定料金なので、突然人気が出たり乱用されたりしても大幅な損失にならないのが良い。
商用サービスとして真面目にやるなら、やはりAWSなどのクラウドで運用して、各サーバを別インスタンスに配置して、サブネットを切って、NATを置いて、監視やレプリケーションやバックアップの仕組みを整えることになるだろう。可用性の要件があるなら、アベイラビリティゾーンをまたがったデプロイとデータレプリケーションを設定するだろう。その場合の費用は結構なものになるだろうが、そこまでサービスが育ったなら、何らかの方法で回収できることだろう。
必要なコンピューティングリソース
平均的なアクティブユーザの毎日の行動を次のように見積もる。各人は、10回の投稿リスト画面表示と、10回の投稿詳細表示と、5回のユーザリスト画面表示と、5回のユーザ詳細画面表示をする。また、500文字の記事を2回投稿して、1個の画像をアップロードする。画像は500KB、サムネイル画像は100KBとする。投稿リスト画面の中には20個の記事のスニペットが含まれ、そこには平均10個のサムネイルが含まれる。
DBの検索系のクエリは、検索とデータ読み出しを総合すると、リスト表示も詳細表示も同程度の負荷とみなす。それが1ユーザ1日あたり10+10+5+5=30回投げられる。つまり、QPSは1万ユーザあたり30/86400*10000=3.472である。ピーク時にはその3倍の10QPS程度が来ると想定される。更新系のQPSは1万ユーザあたり2/86400*10000=0.23であり、ピーク時にはその3倍の0.7QPS程度が来ると想定される。イイネを入れると1QPSくらいだろうか。
画像に関しては、1ユーザ1日あたり、一覧表示でのサムネイル10*20=200個と、投稿詳細表での元画像5個のダウンロードが行われる。サムネイルはキャッシュが利くので、実際の転送数は50個とする。50*100KBで、転送量は5MBとなる。元画像は5*500KBで、2.5MBとなる。つまり合計7.5MBである。1万ユーザあたり75GBであり、ビット数で換算すると600Gbであり、必要スループットは7Mbpsとなる。ピークタイムはその3倍の21Mbps程度が来ると想定される。
つまるところ、DBの負荷は1万ユーザで余裕があるし、10万ユーザでも耐えそうだが、ネットワーク転送量が先に問題になりそうだ。例えばAWSなら0.114ドル/GBなので、1万ユーザで1日あたり8.55ドルもかかる。さくらVPSは定額でネットワーク量もコミコミだが、100Mbpsの共用回線なので、10Mbpsとかで利用制限がかかってもおかしくない。ゆえに、画像配信に関しては1万ユーザに至る前にCDNを導入する必要があるだろう。
何10万ユーザの規模になると、愚直にRDBMSを使っている場合じゃなくなってくるので、再設計が必要になるだろう。バックエンドだけをすげ替えれば、スケールアウトするアーキテクチャにもできるだろうが、今回はそこが目的じゃない。主にフロントエンドを学びたいわけで、バックエンドは単純な方が良い。
機能要件
先に要件を定義すると言いながら、実際のところ、アジャイル的な方法で、プロトタイプを何度か作り直しながら要件を固めていった。よって、画像アップロード以外の機能は既にスクリーンキャプチャがある。ここでは、あたかも要件を一気に固めたかのように列挙する。この要件をAIに読み込ませるだけで実装の雛形ができるように、分かる範囲で細かい要件も挙げてみる。
- / : ルートアドレス(画面なし)
- ログイン後のセッションIDがない状態なら、ログイン画面に自動的に遷移する。
- ログイン後のセッションIDがある状態なら、投稿一覧画面に自動的に遷移する。
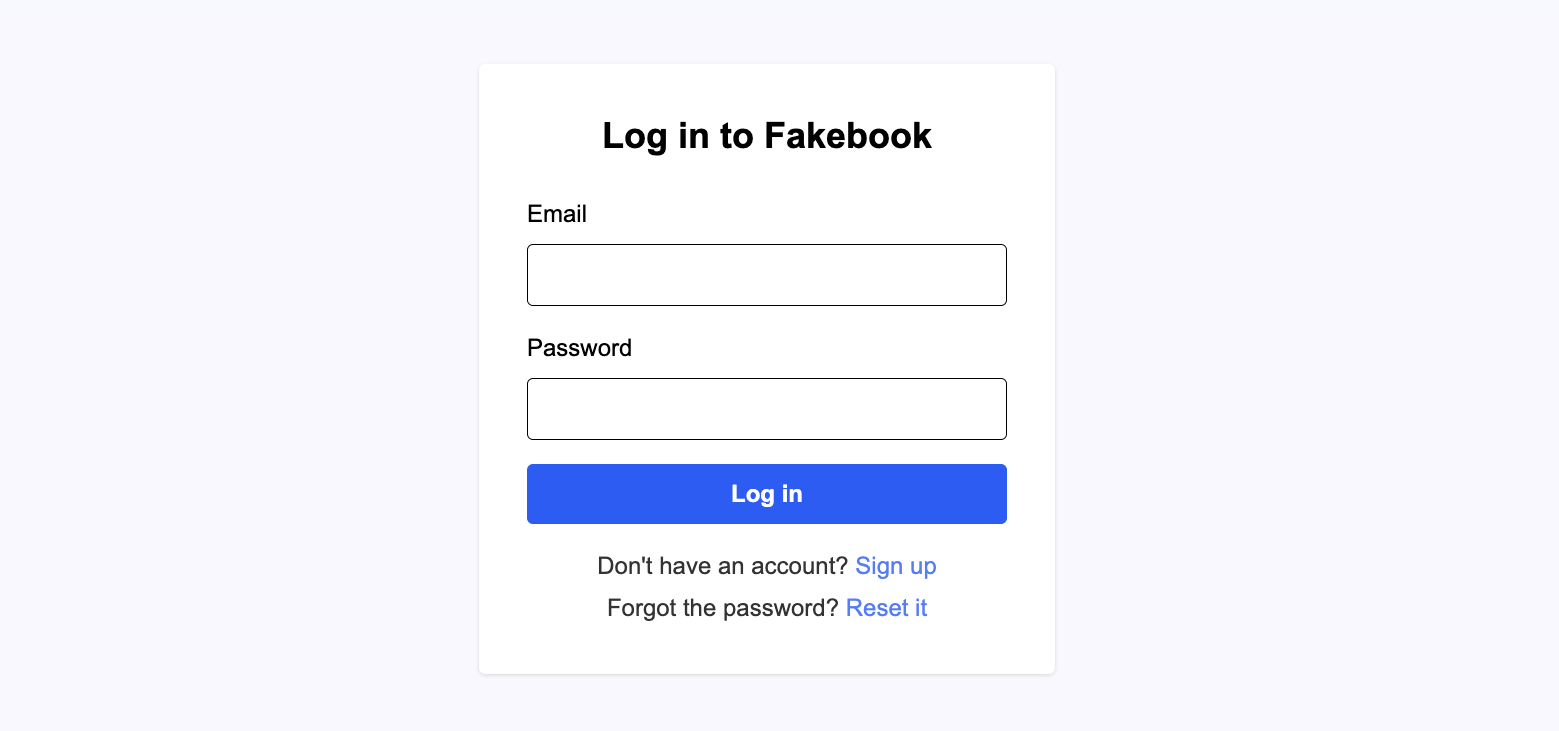
- /login : ログイン画面
- ユーザID(メアド)とパスワードと「ログイン」ボタンがある。押すと、ログイン処理を行い、セッションを生成する。
- ログイン成功なら、投稿一覧画面に遷移する。
- ユーザ登録画面へのリンクが有る
- パスワード再設定画面へのリンクが有る
- 最後にログイン成功した際のユーザIDが該当フォームの初期値として設定される。
- /signup : ユーザ登録画面
- ユーザID(メアド)とパスワードの入力欄と「確認メール送信」ボタンがある。押すと、確認番号をメールを送信する。
- その後、確認番号の入力欄と「ユーザ登録」ボタンが表示され、押すとユーザ登録される。
- ユーザ登録に成功したら、ログイン画面に遷移する。
 |  |  |
- /reset-password : パスワード再設定画面
- メールアドレスの入力欄と「確認メール送信」ボタンがある。押すと、確認番号のメールを送信する。
- その後、確認番号と新規パスワードの入力欄と、「パスワード設定」ボタンが表示され、押すとパスワードが再設定される。
- パスワード再設定に成功したら、ログイン画面に遷移する。
 |  |  |
- ログイン後の画面共通パーツ
- メニューバーがある。場所は画面上端。
- 左端のFakebookロゴの隣に、「posts」と「users」を切り替えられるタブ風のリンクを設置。
- 右端には歯車アイコンがあり、押すとプルダウンが出る。
- 現状では「プロフィール」「設定」「ログアウト」のみが出る。プロフィールは自分のユーザ詳細画面に遷移。
- 歯車アイコンの左隣には検索フォームがある。
- 投稿一覧画面と投稿詳細画面では、投稿の検索機能として動作する
- ユーザ一覧画面とユーザ詳細画面では、ユーザの検索機能として動作する


- /posts : 投稿一覧画面
- 投稿フォームがある。場所は画面中央上側。
- 本文を入力して「投稿」ボタンを押すと、記事を投稿できる。執筆中の記事のプレビューを表示する機能もある。
- 投稿後には、新規の投稿を反映させる。
- 本文を改行で区切って、末尾の非空白行を調べて「#」で始まる行はタグ定義とする。
- "#abc, #xyz" は ["abc", "xyz"] になる "#abc, xyz" は ["abc, xyz"] になる
- 本文は1文字以上5000文字まで、タグは50文字までかつ5個までに制限する。
- 投稿一覧がある。場所は投稿フォームの下。
- 条件に合う投稿を最大20件表示する。一覧の下端にページ送り機能がある。
- 以下の3つのモードをタブ的なボタンで切り替えられる。
- Following : デフォルト。自分とフォロー先ユーザの投稿に絞る
- Liked : 自分がLikeした投稿に絞る。
- All : 全ての投稿。
- including repliesチェックボックス。オンにすると、返信投稿も一覧に含める。デフォルトはオフ。
- oldest first。オンにすると、投稿を古い順に並べる。デフォルトはオフ。
- 検索パラメータ(q=xxx)がある場合、モードをAll、including repliesをオンにした上で、条件に該当するものに絞り込む。
- 一覧の中の各投稿の内容は以下の通り:
- 著者名。文字列を押すとその著者のユーザ詳細画面に遷移
- 投稿日時。投稿後に更新された投稿は更新日時も併記。
- 返信対象。その投稿が返信である場合、返信対象の記事の著者名とともに「In response to xxx」と表示。そのどこかを押すとその投稿に遷移。
- 本文。Markdownからテキストだけを抜き出し、最大200文字をプレーンテキストとして表示。欄のどこかを押すと投稿詳細画面に遷移。
- Likeボタン。押すとLike状態をトグルで切り替える。アイコンの横にLike数を表示。
- 返信ボタン。押すと該当記事の直下に投稿フォームが出現し、返信としての投稿ができる。返信数が1以上の場合、アイコンの横に数を表示。自分が返信した投稿の返信ボタンは濃くなって判別できる。

 |  |
- /posts/{id} : 投稿詳細画面
- 著者名。欄のどこかを押すとその著者のユーザ詳細画面に遷移
- 投稿日時投稿後に更新された投稿は更新日時も併記。
- 本文。Markdownをレンダリング。
- 編集ボタン。操作ユーザが管理者であるか、自分の投稿のみに現れる。押すと直下に投稿フォームが現れる。
- 本文とタグが既存の投稿のデータになっていて、"Save" で提出するとその投稿の内容が書き換えられる。
- 本文を空にすると "Save" が "Delete" に変わって、押すと投稿を削除して、投稿一覧に遷移。
- Likeボタン。押すとLike状態をトグルで切り替える。Like数が1以上の場合、アイコンの横に数を表示。
- Likeユーザリスト。その投稿をLikeしたユーザのリスト。最新10件表示。それ以上ある場合、"..." を押すと100件まで表示。
- 返信ボタン。押すと該当記事の直下に投稿フォームが出現し、返信としての投稿ができる。返信数が1以上の場合、アイコンの横に数を表示。自分が返信した投稿の返信ボタンは濃くなって判別できる。返信をすると返信投稿のリストが書き換わる。
- 返信投稿のリスト。表示形式は投稿一覧画面の投稿一覧と同じ。
- Likeボタン、返信ボタン、ページ送りなども全て投稿一覧のものと同じように動作する。

- /users : ユーザ一覧画面
- ユーザ一覧がある。場所は画面中央。
- 条件に合うユーザを最大20件表示する。一覧の下端にページ送り機能がある。
- 以下の3つのモードをタブ的なボタンで切り替えられる。
- Followees : デフォルト。自分がフォローしているユーザ
- Followers : 自分をフォローしているユーザ
- All : 全てのユーザ
- oldest first。オンにすると、投稿を古い順に並べる。デフォルトはオフ。
- 検索パラメータ(q=xxx)がある場合、モードをAllにした上で、条件に該当するものに絞り込む
- 一覧の中の各ユーザの内容は以下の通り:
- ユーザ名。欄のどこかを押すとその著者のユーザ詳細画面に遷移。
- 管理者の場合、「admin」ラベルが付く。AIモデルが空でない場合、「AI」ラベルが付く。
- フォロー機能。そのユーザが自分の場合、何も表示しない。自分がフォローしているユーザの場合「following」ラベルが付く。ホバーさせると「unfollow」ボタンになり、押すとそれが反映される。それ以外の場合、「follow」ボタンが置かれ、押すとそれが反映される。
- 自己紹介。最大200文字を表示。空なら省略。
- ユーザ名。欄のどこかを押すとその著者のユーザ詳細画面に遷移。

- /users/{id} : ユーザ詳細画面
- ユーザプロフィール欄。
- ユーザ名。欄のどこかを押すとその著者のユーザ詳細画面に遷移。
- 管理者の場合、「admin」ラベルが付く。AIモデルが空でない場合、「AI」ラベルが付く。
- フォロー機能。そのユーザが自分の場合、何も表示しない。自分がフォローしているユーザの場合「following」ラベルが付く。ホバーさせると「unfollow」ボタンになり、押すとそれが反映される。それ以外の場合、「follow」ボタンが置かれ、押すとそれが反映される。
- メアド。そのユーザが自分の場合にのみ表示。
- 自己紹介。最大200文字を表示。空なら省略。
- 自己紹介。空なら非表示。
- AIのパーソナリティ。空なら非表示。
- AIのモデル。空なら非表示。
- 編集ボタン。操作ユーザが管理者であるか、ユーザが自分の場合のみに現れる。押すと直下に編集フォームが現れる。
- ユーザ名と自己紹介が既存のデータになっていて、提出するとそれらの内容が書き換えられる。
- 管理者のみ、メアドの変更フォームが現れる。
- タブ表示欄。「posts」「replies」「followees」「followers」を切り替え。
- postsは、そのユーザの投稿のリスト。表示形式は投稿一覧画面の投稿一覧と同じ。
- followeesは、そのユーザがフォローしているユーザのリスト。followersは、そのユーザをフォローしているユーザのリスト。表示形式はユーザ一覧画面のユーザ一覧と同じ。

 |  |
- /settings : 設定画面
- メアド変更欄がある。メアドを入力して「送信」ボタンを押すとメールが送られる。
- その後、確認ボタンを押すとメアドが変更される。
- メアド変更に成功したら、ログアウトされ、ログイン画面に遷移する。
- パスワード変更欄がある。新規パスワードを入力して「変更」ボタンを押すとパスワードが変更される。
- パスワード変更に成功したら、ログアウトされ、ログイン画面に遷移する。
- 退会欄がある。
- 退会ボタンを押したうえで、「withdrawal」と入力欄に入れて再度退会ボタンを押すと、ユーザが消される。
- 退会に成功したら、ログアウトされ、ログイン画面に遷移する。
- メアド変更欄がある。メアドを入力して「送信」ボタンを押すとメールが送られる。

個々の画面の細かい機能要件や非機能要件については記事を分けて詳述する予定。
DM/チャット機能とコミュニティ機能については割愛している。それらを省くことで、特定のユーザのみが見られる情報が一切なくなるので、メアドとパスワード以外の全てが公開情報という建付けにできる。それでまずは実運用まで持っていってから、付加的な機能を検討する。
非機能要件
非機能要件に特に変わったものはなく、以下の一般的なものを設定した。
- 本番運用では、UAと当システムの間の通信は必ずHTTPSで暗号化する。
- バックエンドのエンドポイントをUAが直接叩くため、バックエンド側に全てのセキュリティ対策を施す
- データフォーマット、データサイズ、文字コードなど、全ての入力パラメータの検証を必ず行う
- CSRF攻撃を防ぐために、バックエンドにCORS制限を設定する。
- 指定したフロントエンドからのアクセスのみを許す。
- リバースプロキシ運用が前提なので、1ホップのプロクシは信用する。
- セッション管理はクッキーで行う。
- TTLは長くて良いが、httponlyかつsecureにする。
- パスワードはハッシュ化してDBに保存する。
- SQLインジェクションに対処すべく、クエリ生成時の入力パラメータのプレースホルダ化を徹底する。
- 目視で確認するとともに、AIにダブルチェックさせる。
- XSSに対処すべく、HTML化の際のエスケープを徹底。
- メール送信等の外部通信でDoSアタックの踏み台にされないように注意。
- メール送信等の全ての外部通信には施行頻度に制限を設ける。
- サブシステムのパスワード等のシークレットをコード内にハードコードしないこと。
- 開発中は.envファイルで管理し、本番稼働し始めたらGitHub上のシークレット等で管理する。
- DBのレプリケーションやバックアップなどの可用性に関しては、PostgreSQLの既存ツールに任せる。
- メディアストレージの可用性に関しては、ストレージのそれに任せる。
- キャッシュには揮発性のデータしか入れない。
- DBからレコードのリストを取得する場合、必ずLIMITを設ける。
- コンテンツ一覧やユーザ一覧などはページネーションを実装する
- LIMITパラメータの上限をバックエンド側で確保する。
- ログに関しては、今のところ要件を設けない。
- ガチで一般ユーザ相手に運用するなら、少なくとも全更新操作をIPアドレスとともに記録する必要があるだろうが、今は気にしない。
開発環境
開発中には、全てのサブシステムをDockerで動かせるようにする。すなわち、フロントエンド、バックエンド、PostgreSQL、MinIO、Redis、PostfixそれぞれをDockerのインスタンスで動かせるようにした上で、フロントエンドとバックエンドはローカルでも動かせるようにしておく。自分がコードを書くサブシステムはローカルで動かした方がいろいろと楽だ。ローカルのマシンはMacbookであり、が、dockerのランタイムにはColimaを使う。DockerとNode.jsが動くなら何でも良い。
開発作業は、Githubのリポジトリを作って、その中にディレクトリ階層を掘るところから始まる。以下の構成にした。
- fakebook/ : プロジェクトルート
- backend/ : バックエンドのソースコードや設定ファイル
- frontend/ : フロントエンドのソースコードや設定ファイル
- db/ : PostgreSQLの設定やSQL
- tests/ : システムテスト関連
- scripts/ : その他、便利ツール
パッケージ管理はnpmで行う。ルートの直下とbackendの下とfrontendの下には、それぞれpackage.jsonを置く。その内容もAIに書かせた。ルートのpakcage.jsonでは、主にDockerインスタンスの起動方法だけを書く。今はこんな感じで、簡易版Makefileみたいな位置づけだ。
{ "name": "fakebook", "private": true, "workspaces": [ "frontend", "backend" ], "scripts": { "docker:reset": "docker-compose down -v && docker-compose build --no-cache", "docker:build": "docker-compose build", "docker:start": "docker-compose up -d", "docker:stop": "docker-compose down", "docker:restart": "docker-compose down ; docker-compose up -d", "docker:dev": "npm run docker:stop && docker-compose up -d db redis smtp", "log:backend": "docker-compose logs backend", "log:frontend": "docker-compose logs frontend", "log:db": "docker-compose logs db", "log:minio": "docker-compose logs minio", "reset-data": "./db/reset-data.sh", "endpoint-test": "./tests/endpoint_test.py", "psql": "docker-compose exec db psql -U fakebook fakebook", "clean": "rm -rf node_modules package-lock.json dist && npm run clean --workspaces && find . -name '*~' -type f -delete" } }
バックエンドとフロントエンドのそれぞれにもpackage.jsonがあるのだが、それぞれを説明する機会に触れることになるだろう。
実際の開発は、docker-compose.ymlを書くところから始まる。これが最も面倒くさいと言っても過言ではない。AIにその解説をさせて、初回の記事は終わろう。
services: db: image: postgres:16 restart: always environment: POSTGRES_USER: ${FAKEBOOK_DATABASE_USER} # DB管理用のユーザー名 POSTGRES_PASSWORD: ${FAKEBOOK_DATABASE_PASSWORD} # 上記ユーザーのパスワード POSTGRES_DB: ${FAKEBOOK_DATABASE_NAME} # 作成されるデータベース名 ports: # Docker内の5432ポートをホスト側の任意のポートに読み替え - "${FAKEBOOK_DATABASE_PORT}:5432" volumes: - db_data:/var/lib/postgresql/data - ./db/init:/docker-entrypoint-initdb.d healthcheck: test: ["CMD-SHELL", "pg_isready -U ${FAKEBOOK_DATABASE_USER} -d ${FAKEBOOK_DATABASE_NAME}"] interval: 5s timeout: 5s retries: 10 start_period: 5s minio: image: minio/minio:RELEASE.2025-07-23T15-54-02Z container_name: minio environment: MINIO_ROOT_USER: ${FAKEBOOK_MINIO_ROOT_USER} # MinIO管理者のユーザー名(AWSのAccessKeyに相当) MINIO_ROOT_PASSWORD: ${FAKEBOOK_MINIO_ROOT_PASSWORD} # MinIO管理者のパスワード(AWSのSecretKeyに相当) entrypoint: ["/bin/sh", "/entrypoint.sh"] command: ["minio", "server", "/data", "--console-address", ":9001"] ports: # Docker内の9000と9001ポートをホスト側の任意のポートに読み替え - "${FAKEBOOK_MINIO_PORT}:9000" - "${FAKEBOOK_MINIO_CONSOLE_PORT}:9001" volumes: - minio_data:/data - ./minio/entrypoint.sh:/entrypoint.sh:ro - ./minio/init.sh:/init.sh:ro restart: unless-stopped redis: image: redis:7 restart: always ports: # Docker内の6379ポートをホスト側の任意のポートに読み替え - "${FAKEBOOK_REDIS_PORT}:6379" command: ["redis-server", "--requirepass", "${FAKEBOOK_REDIS_PASSWORD}"] # ${FAKEBOOK_REDIS_PASSWORD} = Redis接続用パスワード volumes: - redis_data:/data healthcheck: test: ["CMD-SHELL", "redis-cli -a ${FAKEBOOK_REDIS_PASSWORD} PING || exit 1"] interval: 5s timeout: 3s retries: 20 smtp: image: boky/postfix restart: always environment: RELAYHOST: ${FAKEBOOK_SMTP_RELAYHOST} # メール送信の中継サーバ(例: smtp.gmail.com) RELAYHOST_USERNAME: ${FAKEBOOK_SMTP_RELAYHOST_USERNAME} # 中継サーバの認証ユーザー RELAYHOST_PASSWORD: ${FAKEBOOK_SMTP_RELAYHOST_PASSWORD} # 中継サーバの認証パスワード ALLOWED_SENDER_DOMAINS: ${FAKEBOOK_SMTP_SENDER_DOMAINS} # このSMTPから送信を許可する差出人ドメイン ports: # Docker内の587ポートをホスト側の任意のポートに読み替え - "${FAKEBOOK_SMTP_PORT}:587" mailworker: build: context: . dockerfile: backend/Dockerfile depends_on: redis: condition: service_healthy smtp: condition: service_started environment: FAKEBOOK_REDIS_HOST: ${FAKEBOOK_REDIS_HOST} # Redisサーバのホスト名(dockerネットワーク上のサービス名を指定) FAKEBOOK_REDIS_PORT: ${FAKEBOOK_REDIS_PORT} # Redisサーバのポート番号(通常6379) FAKEBOOK_REDIS_PASSWORD: ${FAKEBOOK_REDIS_PASSWORD} # Redis接続用パスワード FAKEBOOK_SMTP_HOST: ${FAKEBOOK_SMTP_HOST} # SMTPサーバのホスト名 FAKEBOOK_SMTP_PORT: ${FAKEBOOK_SMTP_PORT} # SMTPサーバのポート(通常587) FAKEBOOK_MAIL_SENDER_ADDRESS: ${FAKEBOOK_MAIL_SENDER_ADDRESS} # 送信元メールアドレス(例: no-reply@example.com) command: ["node", "dist/mailWorker.js"] restart: unless-stopped backend: build: dockerfile: backend/Dockerfile depends_on: # 各種サブシステムが起動するまで待つ db: condition: service_healthy minio: condition: service_started redis: condition: service_healthy ports: # Docker内の任意ポート(3001)をホスト側の任意のポートに読み替え - "${FAKEBOOK_BACKEND_PORT}:${FAKEBOOK_BACKEND_PORT}" environment: FAKEBOOK_FRONTEND_ORIGIN: ${FAKEBOOK_FRONTEND_ORIGIN} # フロントエンドのURL(CORS許可設定用) FAKEBOOK_BACKEND_HOST: ${FAKEBOOK_BACKEND_HOST} # APIサーバ自身のホスト名 FAKEBOOK_BACKEND_PORT: ${FAKEBOOK_BACKEND_PORT} # APIサーバのポート番号 FAKEBOOK_DATABASE_HOST: ${FAKEBOOK_DATABASE_HOST} # DBホスト名(docker-composeのサービス名dbを指定することが多い) FAKEBOOK_DATABASE_USER: ${FAKEBOOK_DATABASE_USER} # DB接続ユーザー FAKEBOOK_DATABASE_PASSWORD: ${FAKEBOOK_DATABASE_PASSWORD} # DB接続パスワード FAKEBOOK_DATABASE_NAME: ${FAKEBOOK_DATABASE_NAME} # DB名 FAKEBOOK_DATABASE_PORT: ${FAKEBOOK_DATABASE_PORT} # DBポート(通常5432) FAKEBOOK_STORAGE_DRIVER: ${FAKEBOOK_STORAGE_DRIVER} # ストレージドライバ(例: s3) FAKEBOOK_STORAGE_S3_ENDPOINT: ${FAKEBOOK_STORAGE_S3_ENDPOINT} # S3互換ストレージのエンドポイントURL FAKEBOOK_STORAGE_S3_REGION: ${FAKEBOOK_STORAGE_S3_REGION} # S3リージョン FAKEBOOK_STORAGE_S3_ACCESS_KEY_ID: ${FAKEBOOK_STORAGE_S3_ACCESS_KEY_ID} # S3アクセスキー FAKEBOOK_STORAGE_S3_SECRET_ACCESS_KEY: ${FAKEBOOK_STORAGE_S3_SECRET_ACCESS_KEY} # S3シークレットキー FAKEBOOK_STORAGE_S3_FORCE_PATH_STYLE: ${FAKEBOOK_STORAGE_S3_FORCE_PATH_STYLE} # trueならパススタイルアクセス FAKEBOOK_STORAGE_PUBLIC_BASE_URL: ${FAKEBOOK_STORAGE_PUBLIC_BASE_URL} # 公開ファイルのベースURL FAKEBOOK_REDIS_HOST: ${FAKEBOOK_REDIS_HOST} FAKEBOOK_REDIS_PORT: ${FAKEBOOK_REDIS_PORT} FAKEBOOK_REDIS_PASSWORD: ${FAKEBOOK_REDIS_PASSWORD} FAKEBOOK_MAIL_SENDER_ADDRESS: ${FAKEBOOK_MAIL_SENDER_ADDRESS} FAKEBOOK_TEST_SIGNUP_CODE: ${FAKEBOOK_TEST_SIGNUP_CODE} # 開発・テスト用の仮サインアップコード command: ["node", "dist/index.js"] restart: unless-stopped frontend: build: dockerfile: frontend/Dockerfile args: NEXT_PUBLIC_API_BASE: ${FAKEBOOK_BACKEND_API_API_BASE} # フロントのビルド時に埋め込むAPIベースURL depends_on: backend: # バックエンドが起動するまで待つ condition: service_started environment: PORT: ${FAKEBOOK_FRONTEND_PORT} # Next.jsの起動ポート NEXT_PUBLIC_API_BASE: ${FAKEBOOK_BACKEND_API_API_BASE} # ブラウザからAPI呼び出しに使うURL ports: # Docker内の任意ポート(3000)をホスト側の任意のポートに読み替え - "${FAKEBOOK_FRONTEND_PORT}:${FAKEBOOK_FRONTEND_PORT}" command: ["node", "frontend/server.js"] restart: unless-stopped volumes: db_data: minio_data: redis_data:
.envファイルには、docker-compose.ymlに読み込ませる変数が書いてある。
FAKEBOOK_FRONTEND_HOST=frontend FAKEBOOK_FRONTEND_PORT=3000 FAKEBOOK_FRONTEND_ORIGIN=http://localhost:3000 FAKEBOOK_BACKEND_HOST=backend FAKEBOOK_BACKEND_PORT=3001 FAKEBOOK_BACKEND_API_API_BASE=http://localhost:3001 FAKEBOOK_DATABASE_HOST=db FAKEBOOK_DATABASE_USER=fakebook FAKEBOOK_DATABASE_PASSWORD=********* FAKEBOOK_DATABASE_NAME=fakebook FAKEBOOK_DATABASE_PORT=5432 FAKEBOOK_MINIO_HOST=minio FAKEBOOK_MINIO_PORT=9000 FAKEBOOK_MINIO_CONSOLE_PORT=9001 FAKEBOOK_MINIO_ROOT_USER=fakebook FAKEBOOK_MINIO_ROOT_PASSWORD=********* FAKEBOOK_STORAGE_DRIVER=s3 FAKEBOOK_STORAGE_S3_ENDPOINT=http://minio:9000 FAKEBOOK_STORAGE_S3_REGION=us-east-1 FAKEBOOK_STORAGE_S3_ACCESS_KEY_ID=fakebook FAKEBOOK_STORAGE_S3_SECRET_ACCESS_KEY=********* FAKEBOOK_STORAGE_S3_FORCE_PATH_STYLE=true FAKEBOOK_STORAGE_PUBLIC_BASE_URL=http://localhost:9000 FAKEBOOK_REDIS_HOST=redis FAKEBOOK_REDIS_PORT=6379 FAKEBOOK_REDIS_PASSWORD=********* FAKEBOOK_SMTP_HOST=smtp FAKEBOOK_SMTP_PORT=587 FAKEBOOK_SMTP_SENDER_DOMAINS=dbmx.net FAKEBOOK_SMTP_RELAYHOST=[dbmx.net]:587 FAKEBOOK_SMTP_RELAYHOST_USERNAME=postfix@dbmx.net FAKEBOOK_SMTP_RELAYHOST_PASSWORD=********* FAKEBOOK_MAIL_SENDER_ADDRESS=noreply@dbmx.net FAKEBOOK_TEST_SIGNUP_CODE=000000
一連のpackage.jsonとdocker-compose.ymlと.envを書いておくと、システムの起動はコマンド数発でいける。全てをDockerで動かすなら、以下のようにする。
$ cd fakebook $ npm install $ npm run docker:build $ npm run docker:start
開発の進め方
一連の連載で述べるアーキテクチャは、水平分散(=スケールアウト)には手を出さず、その手前まで最適化する。すなわち、ホストマシン1台で運用できる状態から始めて、DBサーバやストレージサーバを分割して運用し、それらのレプリケーションで負荷分散を図るところまでは、同一の実装で運用できるようにする。水平分散をしないスケールアップ戦略だけでは、10万ユーザあたりで限界を迎えるだろう。そこまで成長できたならサービスとしては成功の部類に入るだろう。
いきなり100万ユーザを捌けるシステムを運用するのは現実的ではない。多大な初期投資をしてもそこまで成長する保証はどこにもないからだ。大規模サイトの開発や運用に必要なスキルセットを持つ人材をいきなり獲得するのも難しい。それよりは、頑張れは10万ユーザを捌ける実装をして、比較的少ない初期投資で運用を開始し、実運用と改良を続けて各人員が経験を詰むべきだ。10万ユーザに至るまでの猶予期間で、システムの課題を洗い出し、それに基づいたスケールアウト戦略を編み出して、実施するのだ。システムがスケールするだけではだめで、開発体制や運用体制がそれについていけるように組織をスケールさせねばならない。
今回の目的である「自身のフルスタック化」を達成するためには、100万人のユーザは必要ない。エンドユーザ相手の開発経験と運用経験を詰むだけなら、ユーザは1000人も居れば十分だ。まずは10万ユーザに耐える単純かつ堅牢なバックエンドを作り上げた上で、10万ユーザを獲得し得るUXを追求したい。
AIを駆使する開発という観点では、仕様をできるだけ詳しく記録しておくことが望ましい。スペック駆動開発などと言われるが、仕様をAIに読ませて、システムのプロトタイプを生成させて、それを修正していくという開発方式がある。必要十分な粒度で仕様を定義しておくと、生成されるプロトタイプの精度が上がり、修正に必要なコストが最小化する。今回は、このブログがまさに仕様定義になっている。この連載を読み込ませるだけで、Fakebookとほぼ同じシステムが生成されることを目標として、記事を執筆していく。現状のAIモデルは一般的な開発技法については人間より詳しい知識を持っているが、個々のドメインの知識は必ずしもそうではない。そこで、ある程度経験のある私の知識を入力することで、その補填ができる。
AIにとって自明な一般知識と、AIが知らなそうな知識を分けて考え、後者について詳述するのが重要だ。AIがドメイン特化の知識において比較的不得手だと書いたが、それよりも不得手というか、原理的に不可能なのは、利用者が何を達成したいかという要件を予測することである。利用者の情報は学習データに無いのだから当然だ。よって、何がやりたいのかを明確化することこそが重要になる。
まとめ
FakebookというSNSを実装しながら巷でフルスタックエンジニアと呼ばれる人達に必要なスキルセットの多くを学んでいくことにした。現状で画像管理とAI関係の機能以外のほとんどはできているのだが、その設計の実装について、メモがてら、これから少しずつここにまとめていく。コードベースはこちらにある。