辞書検索システムで例文の全文検索を実装するために、下層のC++/Pythonライブラリに手を加えた。ついでにRubyでも同等の機能を実装した。すなわち、DBMライブラリTkrzwのPythonバインディングやRubyバインディングやJavaバインディングにて、コールバック関数でレコードを参照したり更新したりするProcessメソッドをサポートした。さらに、データベースファイルやテキストファイルから特定のパターンに該当するレコードを抜き出すSearch系メソッドの強化もした。Tkrzw 1.0.25およびTkrzw-Python/Ruby/Java 0.1.29から利用できる。
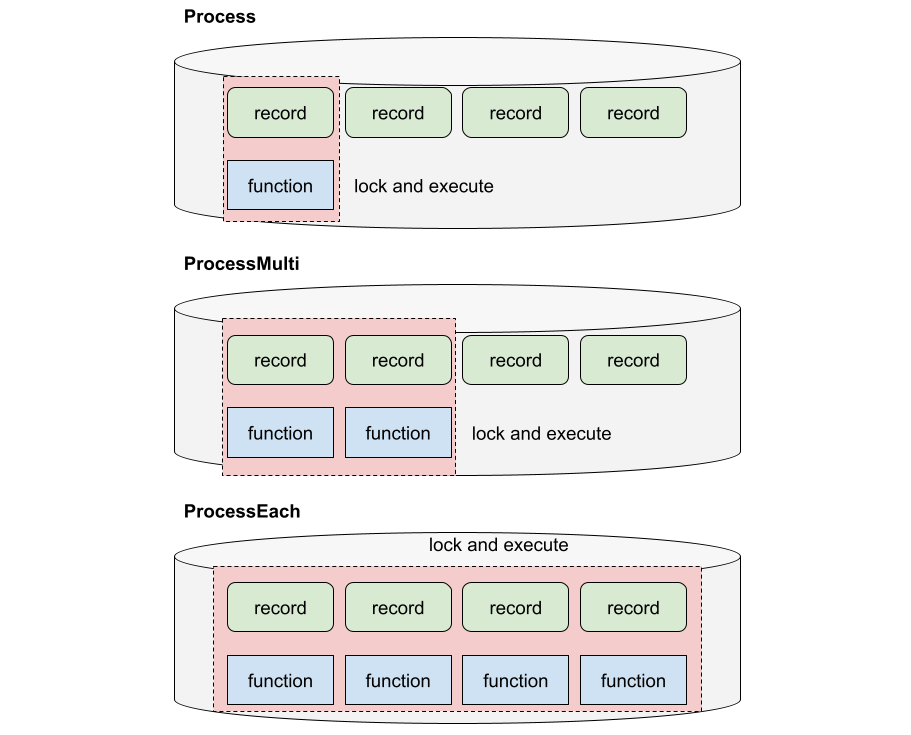
任意のコールバック関数でレコードをアトミックに更新するProcess系メソッドがあるのがTkrzwの売りの一つだが、複雑な概念なので、使いこなしている人は少ない。なので、C++でしかサポートされていなかった。しかし、辞書検索システムの語義の全文検索を実装するにあたって使いたくなったので、PythonとRubyとJavaでもサポートしてみた。ついでにその使い方を改めて紹介したい。
まず、参考のために、DBMの基本的な使い方を説明する。普通にSetメソッドでレコードを追加して、それを表示するPythonプログラムだ。
import tkrzw
# データベースを開いて初期化する。
dbm = tkrzw.DBM()
dbm.Open("casket.tkh", True, truncate=True)
# データベースにレコードを追加。
# バイト列でも文字列でも数値でも受け取るが、バイト列に変換されて保存される。
dbm.Set("japan", "tokyo")
dbm.Set(b"thai", b"bangkok")
dbm.Set(123, 4567)
# データベースからレコードを取り出す。Getはバイト列、GetStrは文字列を返す
print(dbm.Get("japan")) # -> b"tokyo"
print(dbm.GetStr("thai")) # -> "bangkok"
print(dbm.GetStr("123")) # -> "4567"
print(dbm.GetStr("arimasen")) # -> None
# データベースを閉じる。
dbm.Close()RubyやJavaだとこんな感じ。どの言語でもだいたいオンメモリの連想配列と同じ使い方になる。
import tkrzw.*
# データベースを開いて初期化する。
dbm = tkrzw::DBM.new
dbm.open("casket.tkh", true, truncate: true)
# データベースにレコードを追加。
# 文字列でも数値でも受け取るが、文字列に変換されて保存される。
dbm.set("japan", "tokyo")
dbm.set("thai", "bangkok")
dbm.set(123, 4567)
# データベースからレコードを取り出す。
p dbm.get("japan") # -> "tokyo"
p dbm.get("thai") # -> "bangkok"
p dbm.get("123") # -> "4567"
p dbm.get("arimasen") # -> nil
# データベースを閉じる。
dbm.closeimport tkrzw.*;
public class Example1 {
public static void main(String[] args) {
// データベースを開く
DBM dbm = new DBM();
dbm.open("casket.tkh", true, "truncate=true");
// データベースにレコードを追加。
dbm.set("first", "hop");
dbm.set("second", "step");
dbm.set("third", "jump");
// データベースからレコードを取り出す
System.out.println(dbm.get("first"));
System.out.println(dbm.get("second"));
System.out.println(dbm.get("third"));
// Checks and deletes a record.
if (dbm.contains("first")) {
dbm.remove("first");
}
// データベースを閉じる
dbm.close();
}
}PythonのProcessメソッドには、キーとコールバック関数を渡す。そうすると、キーに該当するレコードをロックした状態で、コールバック関数が呼ばれ、そのパラメータとしてレコードのキーと値が渡される。該当のレコードが存在しない場合にもコールバック関数が呼ばれるが、値としてはNoneが渡される。キーと値はバイト列として扱われるので注意。
def PrintRecord(key, value):
if value == None:
print("miss: " + key.decode())
else:
print("found: " + key.decode() + "=" + value.decode())
dbm.Process("japan", PrintRecord, False) # "found: japan=tokyo"と印字
dbm.process("japan", false) {|key, value|
if value == nil
p "miss: " + key
else
p "found: " + key + "=" + value
end
}Javaだとこんな感じ。Java8からJavaにもラムダ式が導入されて、かなり書きやすくなった。
dbm.process("japan", (key, value) -> {
if (value == null) {
System.out.println("miss: " + new String(key));
} else {
System.out.println("found: " + new String(key) + "=" + new String(value));
}
return null;
}, true);以後、Pythonだけで説明する。RubyやJavaでもだいたい同じ書き方になる。コールバック関数がNone以外の値を返すと、その値はバイト列に変換された上で、レコードの新たな値になる。更新を行う際には、Processの第3引数はTrueにすること。これはロックの種類を共有ロックから排他ロックに切り替える。
def UpdateRecord(key, value):
if value == None:
new_value = "inai inai baa"
else:
new_value = "I love " + value.decode()
return new_value
dbm.Process("japan", UpdateRecord, True)
dbm.Process("china", UpdateRecord, True)
print(dbm.GetStr("japan")) # "I love Tokyo"と印字
print(dbm.GetStr("china")) # "inai inai baa"と印字既存のレコードを削除したい場合には、コールバック関数はFalseを返す。偽に評価される値ではなく、Falseオブジェクトそのものである必要がある。
def RemoveRecord(key, value):
return False
dbm.Process("japan", RemoveRecord, True)
dbm.GetStr("japan") # -> Noneコールバック関数を呼んで嬉しいことは二つある。ひとつは、既存のレコードの状態によって更新値を変えたい場合に、Getで検索してからSetで更新するのにかかる2回の検索処理を1回分で済ませられることだ。もうひとつは、GetしてからSetするまでの間に他のスレッドがそのレコードの値を更新することで起こるレースコンディションを防げることだ。
アクセスカウンタの例を考えると分かりやすい。各ページのファイル名をキーにして、その訪問数を値にしたデータベースを作る。訪問数を更新する際には、既存の値に1を足す処理をアトミックに行う必要がある。既存の値がなければ1を設定する。それをProcessでやるなら以下のように書く。実際にはIncrementという専用のメソッドがあるけども。
def CountUpRecord(key, value):
return int(value) + 1 if value else 1
dbm.Process("/foo.html", CountUpRecord, True)
dbm.Process("/foo.html", CountUpRecord, True)
dbm.GetStr("/foo.html") # -> "2"ラムダ式を使うともっと簡潔に書ける。とはいえ、読みにくいとも言えるので、慣れた人だけどうぞ。
dbm.Process("/foo.html", lambda k, v: int(v) + 1 if v else 1, True)複数のレコードの参照と更新をアトミックに行うProcessMultiというメソッドもある。これは、「キーとコールバック関数のタプル」のリストを受け取る。各要素は指定した順番で実行される。
def PrintRecord(key, value):
if value == None:
print("miss: " + key.decode())
else:
print("found: " + key.decode() + "=" + value.decode())
dbm.ProcessMulti([
("japan", PrintRecord),
("thai", PrintRecord)], False)ProcessMultiはデータベースのアトミック操作における最強の柔軟性を提供してくれる。典型的な例として、銀行口座のアカウント間の送金を考えよう。アカウントAの値を減らして、その分だけアカウントBの値を増やすという操作をアトミックに行うのだ。Pythonのクロージャは外部変数への代入ができないので、コールバック関数間の状態の共有にはdictやlistである外部変数の中の要素を使う。
# 銀行口座とその金額を設定。
dbm.Set("A", 10000)
dbm.Set("B", 20000)
# 送金処理の内部状態。
remittance_value = 10
remittance_state = {}
# 送金元の金額を減額する関数。
def RemitValueFrom(key, value):
if not value:
remittance_state["error"] = "送金元がない"
return None
value = int(value)
if value < remittance_value:
remittance_state["error"] = "送金元の残金が足りない"
return None
return value - remittance_value
# 送金先の金額を増額する関数。
def RemitValueTo(key, value):
if "error" in remittance_state:
return None
return int(value or 0) + remittance_value
# アトミックに二つの関数を実行する。
dbm.ProcessMulti([("A", RemitValueFrom), ("B", RemitValueTo)], True)
dbm.GetStr("A") # -> 9990
dbm.GetStr("B") # -> 20010Process系メソッドがいかに柔軟で強力かおわかりいただいただろうか。アプリケーション層でMutexとかを使って排他制御するとバグの温床になるので、データベースの整合性はデータベース自身に確保させるのが良い。スレッドを使わない場合でも、処理効率の点ではProcess系を使いたくなることがあるだろう。というか、GetしてからSetするなんて電力の無駄じゃないか。そのあたりに心を砕かないなら、DBMを使う意味がない。
辞書検索システムはスレッドは使わないし、個人で使っている限りはそこまで高速である必要もない。しかし、例文の全文検索を実装するにあたって、全てのレコードにコールバック関数を適用するProcessEachメソッドがPythonにも欲しくなった。なぜかというと、ハッシュデータベースの外部イテレータは遅いからだ。堅牢性や並列更新性能を追求した結果、レコード間の連結リストを動的に更新するのを放棄したので、外部イテレータはハッシュバケットの各々を起点にしてそこに連なるレコードを取り出していく実装になっている。一方で、レコードが更新されないと仮定できるならば、データベースファイルの先頭から末尾まで順に読み込むことで全てのレコードにアクセスすることができる。シーケンシャルアクセスなので、ストレージやファイルシステムのキャッシュ構造の恩恵もあり、テキストファイルを読んでいるのと同等の効率で読み出しが行える。ProcessEachメソッドでwritableパラメータが偽の場合にはそのモードが発動する。
擬似的なユースケースをテストコードに落とし込んでみよう。個々のレコードは辞書の個々の見出し語のデータを保持するが、それはdictの中にlistが入る構造になっている。実際に保存されるデータはJSON形式でシリアライズされる。この中から、対訳文の日本語部分に着目して検索を行う。その操作をProcessEachを使って実装する。
# データベースを開いて初期化する。
dbm = tkrzw.DBM()
dbm.Open("casket.tkh", True, truncate=True)
# JSONテストデータを投入する。
for i in range(10):
examples = []
for j in range(100):
example = {
"en": "I am student {} in class-{}.".format(j, i),
"ja": "私は{}組の生徒{}です。".format(i, j),
}
examples.append(example)
record = {"class": i, "example": examples}
value = json.dumps(record, separators=(",", ":"), ensure_ascii=False)
dbm.Set(i, value)
# 下記の関数が使うパラメータ
query = "生徒80です。"
max_examples = 5
matched_examples = []
# JSONテストデータを復元して examle["ja"] の値の全文検索を行う関数。
def SearchJaExamples(key, value):
# イテレーションの最初と最後に入るvalue==Noneの呼び出しを無視する。
if not value: return None
# 既に結果が満足している場合には残りを省いて高速化する。
if len(matched_examples) >= max_examples: return None
# JSONをデシリアライズしてレコードデータを復元
record = json.loads(value)
# 各例文を見る。
for example in record["example"]:
if len(matched_examples) >= max_examples: return None
text = example["ja"]
# 愚直に文字列の中間一致を調べる
if text.find(query) >= 0:
# 結果はmatched_examplesに入れる
matched_examples.append(text)
# 上述の関数をアトミックに実行する。
dbm.ProcessEach(SearchJaExamples, False)
print(matched_examples)
# データベースを閉じる。
dbm.Close()繰り返しになるが、外部イテレータを使っても同じことができる。dbm.ProcessEach(...) のところを以下のように書き換えてもよい。
for key, value in dbm: SearchJaExamples(key, value)
しかし、外部イテレータを使ったループの中身を関数にするだけで効率化するのだから、そうしない手はない。効率のことを言うなら検索用のインデックスをちゃんと作った方がいいのだけれど、例文の全文検索なんて私がデバッグや興味本位で使うだけなので、1秒以内に終われば十分だ。そういう意味では外部イテレータを使ってもよいのだが、ProcessEachを使った書き換えは別途のインデックスをメンテするよりも遥かに楽なので、とりあえず実装してみた。
ここで残念なお知らせである。ProcessEachメソッドによって、データベースからデータを取り出す処理は著しく高速化したのだが、JSONをデシリアライズする処理がボトルネックになって、全体としては大して高速化しないことが判明した。1クエリあたり数十秒かかることもあり、これでは実用にならない。
もうちょい抜本的にやるしかない。例文だけをTSVファイルとして別途保存しておいて、それをgrep的にスキャンすればよさそうだ。例えば以下のようなデータをデータベースから抽出する。
Shining star, I spell it to infinite imagination. シャイニングスター綴れば無限のイマジネーション。 A world with magical power spreads through. 魔法が使えるような世界が広がる。 I'll believe of my sensation. 自分の感覚に素直になろう。
このファイルを検索して "magical power" を含む文を抜き出したいとする。仮にegrepを呼び出すなら、以下のコマンドになる。
$ egrep -i '\Wmagical power\W' union-examples.tsv
実際に50万対の例文を抜き出したファイルを作り、それに対して上記コマンドを実行してみた。驚くべきことに、上記のコマンドは0.24秒で終わった。GNU grepの最適化は素晴らしく、正規表現エンジンが高速なだけではなく、ファイル全体をmmapして処理するなどの工夫が奏功しているっぽい。
インデックスを作らなくても、50万文対くらいならgrepコマンドは一瞬で処理してくれる。これをベンチマークとして、同等の処理をPythonから実行すればよい。Pythonからパイプ接続でgrepを呼んでその出力を取得するという誘惑に駆られたが、プロセスを起動する負荷がかかるのはちょっといただけない。よって、Tkrzwに同等の機能を組み込む方向で検討する。
Tkrzwにはファイル入出力を抽象化したFileクラスがあり、そのSearchメソッドは正規表現もサポートしている。C++標準の正規表現エンジンを使って、該当する行を抜き出すのだ。これもmmapによる入出力なので、それをPythonから呼び出せば、grepにより近い速度が得られる。使用例は以下のようになる。
import tkrzw
input_file = tkrzw.File()
input_file.Open("union-examples.tsv", False).OrDie()
lines = input_file.Search("regex", "(?i)\Wmagical power\W", 100)
print(lines)
input_file.Close()上記を実行すると、3.48秒かかる。遅い。なぜだ。入出力が遅いのか、正規表現エンジンが遅いのか、その両方か。切り分けるために、これを単なる文字列中間一致の実装に変えてみる。
import tkrzw
input_file = tkrzw.File()
input_file.Open("union-examples.tsv", False).OrDie()
lines = input_file.Search("contain", "magical power", 100)
print(lines)
input_file.Close()今度は0.31秒で実行できた。grepの0.24秒には負けるが、Python層のオーバーヘッドを考えれば、そこそこいい勝負になっている。つまり、libstdc++の正規表現エンジンの効率がgrepのそれに劣っていると言わざるを得ない。
GNU grepの正規表現エンジン(GNU regex)を組み込むという手も考えたが、面倒くさい。しかし、ケースインセンシティブと単語境界を加味した検索処理くらいなら、そもそも正規表現を使う必要はない。そのような関数をC++で実装すればいい。
bool StrCaseWordContain(std::string_view text, std::string_view pattern);
既存のFile::Searchは比較関数を注入できる仕様なので、上記関数を実装してぶっこめば完成だ。Pythonからも呼び出せるようにしておいた。
import tkrzw
input_file = tkrzw.File()
input_file.Open("union-examples.tsv", False).OrDie()
lines = input_file.Search("containcaseword", "magical power", 100)
print(lines)
input_file.Close()実行時間は0.44秒とやや遅くなったが、所望の挙動が実用的な時間で実現できた。やっぱシステムの骨格はPythonなりRubyなりJavaなりで書いて、ボトルネックだけC++で置き換えるという戦略は良い。そしてTkrzwはその際の強力な道具になる。私が欲しいと思った機能は粗方入れているので、「ぼくのかんがえたさいきょうのでーたべーすらいぶらり」の地位は少なくとも私にとっては揺るぎない。
ちなみに、egrepで0.24秒だったコマンド処理は、単語境界を無視して fgrep -i "magical power" などとすると0.091秒、ケースの吸収も諦めて fgrep "magical power" などとすると、0.052秒まで高速化する。それに比べると、私が実装したStrCaseWordContain関数を使った場合の0.45秒は遅い。libstdc++の正規表現エンジンを使った場合の3.4秒よりはだいぶ早いとはいえ、正直負けた気分だ。fgrepが高速であることの一因としてBM(Boyer-Moore)法などの高速なアルゴリズムを使っているからという話があるので、BM法を実装して、かつ複数のテキストの照合で前処理のテーブルを再利用するようにしてみたが、むしろ遅くなってしまった。多少最適化を頑張ったところで、fgrepには勝てる気がしない。
ところで、C++標準の正規表現はデフォルトではECMAScriptの書式になっている。オプションでPOSIX基本正規表現やPOSIX拡張正規表現やAWK正規表現に変えられるが、それらで性能が変わるかどうか試してみた。結論としては、性能は全く変わらなかった。それより、icaseオプションでケースインセンシティブにすると性能が半減するのが興味深い。正規表現でケースインセンシティブな比較をするよりは、比較対象を小文字に正規化してから比較した方が早いかもしれない。今となっては、正規表現を使わないで済むように変更したので、どうでもいい話だけれども。
まとめ。例文の全文検索を実現するにあたり、下層のデータベースライブラリTkrzwに手を加えた。まずは任意のコールバック関数が実行できるProcess系メソッドを実装したが、それでは力不足だったので、ファイルを分けた上でその探索を高速化するSearchメソッドを強化して、実用的なシステムに仕上げた。統合英和辞書を構築運用するための大規模データを使った処理が、分散処理もせずに私のボロいノートPC上だけで完結しているのは、ひとえにTkrzwとその周辺でのチリツモの最適化のおかげである。
そんなこんなで、統合英和辞書の検索システムで例文の全文検索が可能になっている。「索引」のプルダウンで「例文」を選んでから、検索窓に適当な文字列を入れて検索されたい。英語でも検索すれば単語境界を加味して英文を検索してくれるし、日本語を入力すれば単に中間一致で訳文を検索してくれる。50万件を総当り探索しているが、ちゃんと0.5秒以内に結果が表示されるようになった。