Tkrzwの便利機能の一つとしてセカンダリインデックスがあるが、それをC/C++/Java/Python/Ruby/Goの各言語で利用可能にした。本記事では言語毎の使い方を説明し、その使い勝手を比較する。
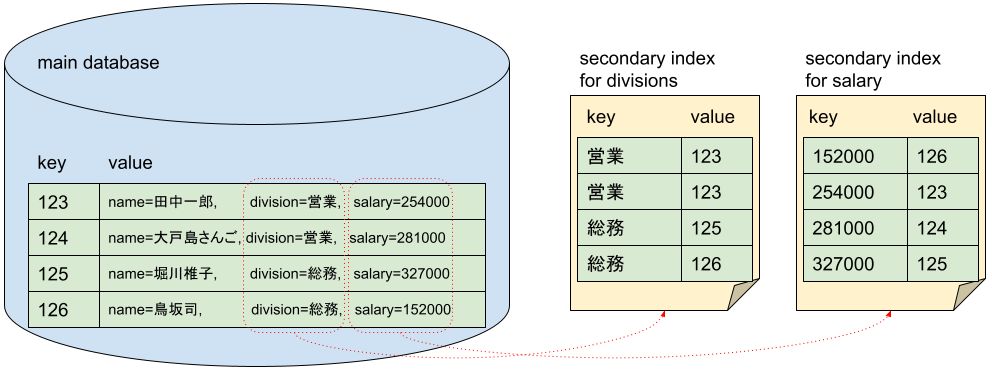
典型的なデータベースにおいては、主キーを検索キーにして、それ意外の属性を適当にシリアライズして保存する。リレーショナルデータベースでは属性は列として表現されるだろうし、オブジェクトデータベースならオブジェクトの任意のフィールドとして表現されるだろう。例えば以下のような感じだ。
| 社員ID(主キー) | 氏名 | 部署 | 給料 |
| 123 | 田中一郎 | 営業 | 254000 |
| 124 | 大戸島さんご | 営業 | 281000 |
| 125 | 堀川椎子 | 総務 | 327000 |
| 126 | 鳥坂司 | 総務 | 152000 |
最も単純化されたデータベースであるDBMでこれを扱うとすると、社員IDをキーにして、その他の属性を適当にシリアライズしたものを保存することになる。擬似コードは以下のようになる。シリアライズはJSONでやるとしようか。
# 構築 person = { "id": "123", "name": "田中一郎", "division": "営業", "salary": "250000", } key = person["id"] value = json.dumps(person) people_database[key] = value # 検索と表示 value = people_database.get("123") if not value: raise KeyError("行方不明!") person = json.loads(value) print(person)
この方法だと、主キーである社員ID以外では検索できない。部署に所属する人員の一覧を得るには、grep的に全てのレコードをスキャンしてフィルタするしかない。
それでは遅すぎて困るという場合には、セカンダリインデックスを使う。セカンダリインデックスとは、任意の検索キーと主キーのペアのデータベースである。冒頭の図を参照されたい。ここでは、部署名と社員IDのペアを収めたセカンダリインデックスを作ることにしよう。そうすると、部署名をキーにしてそれに該当する社員IDの一覧が得られるので、それから元のデータベースを調べればよい。擬似コードは以下のような感じだ。
# 構築 for person in person_list: division_index.Add(person["id"], person["division"]) # 検索と表示 id_list = division_index.GetValues("営業部") for id in id_list: value = people_database.get(id) if not value: raise KeyError("不整合だよ!") person = json.loads(value) print(person)
てことで、DBMとセカンダリインデックスがあれば、非常に簡単にデータベースプログラミングができる。実装の細かいことは以前の記事を参照されたい。
セカンダリインデックスは便利なのだが、今までC++のインターフェイスしか提供していなかった。B+木さえ提供すれば比較関数とシリアライザを適当に書いてユーザ側でセカンダリインデックスを実装できるはずなので、いいかなと思って。というか自分はC++を使っていたので、手抜きしていた。
先日、Go言語でセカンダリインデックス使いたいという人が出てきたので、暇つぶしも兼ねて実装してみたところ、「これ便利じゃね?」と思った。家計簿とかCMSとかゲームとか、何でもいいのだが、ちょっとしたプログラムでのデータ管理機能を自作するのに、いちいちスキーマとか考えなくてよくなる。もちろん比較関数とかシリアライザとかを実装する必要もない。簡単なことは簡単にだ。
セカンダリインデックスをC++でしか提供しなかった理由はもうひとつある。主データベースの更新とセカンダリインデックスの更新をアトミックに行う機構を実現するには、コールバック関数とかを駆使してかなり込み入ったことをしなければいけないからだ。しかし、マルチスレッドでの並列処理性能を求めている人は実際には少数で、潜在的なユーザの9割方はスレッドを使っていないか、使っていたとしてもDB更新処理の並列性を強く追求してはいないかだろう。スレッドを使っていないならアトミック性を考える必要はないし、並列性を追求していないならクリティカルセクションで保護すれば話は済む。
ということで、Java/Python/Ruby/Goにおいてセカンダリインデックスを使えるAPIを提供することにした。機能は単純化して、セカンダリインデックスだけを管理するAPIにする。セカンダリインデックス自身はスレッドセーフだが、主データベースとの間のアトミック性については何もしないということだ。この割り切りをすると、値の重複が可能な連想配列のような、つまりC++のstd::multimapのような、単純なAPIとして提供することができる。実際にコードを走らせたい場合、Tkrzwの最新版(1.0.29以降)と各言語バインディングの最新版(0.1.31以降)をインストールすること。
せっかく多数の言語をサポートしたので、同じ処理をそれぞれの言語で書くとどうなるかを並べて見てよう。まずはC(C99)から。確保したリソースを自分で解放するのが重要だ。API文書はこちら。
#include <stdio.h> #include <stdlib.h> #include "tkrzw_langc.h" int main(int argc, char** argv) { // インデックスを開く。 TkrzwIndex* index = tkrzw_index_open("casket.tkt", true, "truncate=true,num_buckets=100"); // 部署と名前(主キー)のインデックスにレコードを加える。 tkrzw_index_add(index, "general", -1, "anne", -1); tkrzw_index_add(index, "general", -1, "matthew", -1); tkrzw_index_add(index, "general", -1, "marilla", -1); tkrzw_index_add(index, "sales", -1, "gilvert", -1); // アンが総務から営業に異動する。 tkrzw_index_remove(index, "general", -1, "anne", -1); tkrzw_index_add(index, "sales", -1, "anne", -1); // 部署毎に人員を表示する。 const char* divisions[] = {"general", "sales"}; for (int i = 0; i < sizeof(divisions) / sizeof(*divisions); i++) { const char* division = divisions[i]; printf("%s\n", division); int32_t num_members = 0; TkrzwStr* members = tkrzw_index_get_values(index, division, -1, 0, &num_members); for (int j = 0; j < num_members; j++) { printf(" -- %s\n", members[j].ptr); } tkrzw_free_str_array(members, num_members); } // イテレータでインデックスの全ての内容を表示する。 TkrzwIndexIter* iter = tkrzw_index_make_iterator(index); tkrzw_index_iter_first(iter); char *key, *value; while (tkrzw_index_iter_get(iter, &key, NULL, &value, NULL)) { printf("%s: %s\n", key, value); free(value); free(key); tkrzw_index_iter_next(iter); } tkrzw_index_iter_free(iter); // インデックスを閉じる。 tkrzw_index_close(index); return 0; }
次はC++。コンテナとスマートポインタのおかげでリソース管理がめちゃ楽になっている。API文書はこちら。
#include <map> #include <string> #include <vector> #include "tkrzw_index.h" int main(int argc, char** argv) { // インデックスを開く。 tkrzw::PolyIndex index; const std::map<std::string, std::string> open_params = {{"num_buckets", "100"}}; index.Open("casket.tkt", true, tkrzw::File::OPEN_TRUNCATE, open_params).OrDie(); // 部署と名前(主キー)のインデックスにレコードを加える。 index.Add("general", "anne").OrDie(); index.Add("general", "matthew").OrDie(); index.Add("general", "marilla").OrDie(); index.Add("sales", "gilbert").OrDie(); // アンが総務から営業に異動する。 index.Remove("general", "anne").OrDie(); index.Add("sales", "anne").OrDie(); // 部署毎に人員を表示する。 const std::vector<std::string> divisions = {"general", "sales"}; for (const auto& division : divisions) { std::cout << division << std::endl; const std::vector<std::string>& members = index.GetValues(division); for (const auto& member : members) { std::cout << " -- " + member << std::endl; } } // イテレータでインデックスの全ての内容を表示する。 const std::vector<std::string> divisions = {"general", "sales"}; for (const auto& division : divisions) { std::cout << division << std::endl; const std::vector<std::string>& members = index.GetValues(division); for (const auto& member : members) { std::cout << " -- " + member << std::endl; } } // インデックスを閉じる。 index.Close().OrDie(); return 0; }
次はJava。GC方式なのでリソース管理が楽ちん。ファイルやイテレータのようにその場で解放したいリソースは明示的に解放処理を呼ばにゃならんが。API文書はこちら。
import tkrzw.*; public class Example { public static void main(String[] args) { // インデックスを開く。 Index index = new Index(); index.open("casket.tkt", true, "truncate=True,num_buckets=100").orDie(); // 部署と名前(主キー)のインデックスにレコードを加える。 index.add("general", "anne").orDie(); index.add("general", "matthew").orDie(); index.add("general", "marilla").orDie(); index.add("sales", "gilbert").orDie(); // アンが総務から営業に異動する。 index.remove("general", "anne").orDie(); index.add("sales", "anne").orDie(); // 部署毎に人員を表示する。 String[] divisions = {"general", "sales"}; for (String division : divisions) { System.out.println(division); String[] members = index.getValues(division, 0); for (String member : members) { System.out.println(" -- " + member); } } // イテレータでインデックスの全ての内容を表示する。 IndexIterator iter = index.makeIterator(); iter.first(); while (true) { String[] record = iter.getString(); if (record == null) break; System.out.println(record[0] + ": " + record[1]); iter.next(); } iter.destruct(); // インデックスを閉じる。 index.close().orDie(); } }
次はPython。リファレンスカウント方式なので、リソース管理の観点ではC++っぽいノリ。おまけ機能として、iterableプロトコルにも対応しておいた。API文書はこちら。
import tkrzw # インデックスを開く。 index = tkrzw.Index() index.Open("casket.tkt", True, truncate=True, num_buckets=100).OrDie() # 部署と名前(主キー)のインデックスにレコードを加える。 index.Add("general", "anne").OrDie() index.Add("general", "matthew").OrDie() index.Add("general", "marilla").OrDie() index.Add("sales", "gilbert").OrDie() # アンが総務から営業に異動する。 index.Remove("general", "anne").OrDie() index.Add("sales", "anne").OrDie() # 部署毎に人員を表示する。 for division in ["general", "sales"]: print(division) members = index.GetValuesStr(division) for member in members: print(" -- " + member) # イテレータでインデックスの全ての内容を表示する。 iter = index.MakeIterator() iter.First() while True: record = iter.GetStr() if not record: break print(record[0] + ": " + record[1]) iter.Next() # iterableプロトコルを使ったイテレーション。 for key, value in index: print(key.decode() + ": " + value.decode()) # インデックスを閉じる。 index.Close().OrDie()
次はRuby。GC方式なので、リソース管理の観点ではJavaっぽいノリ。おまけ機能として、イテレータブロックにも対応しておいた。API文書はこちら。
require 'tkrzw' # インデックスを開く。 index = Tkrzw::Index.new index.open("casket.tkt", true, truncate: true, num_buckets: 100).or_die # 部署と名前(主キー)のインデックスにレコードを加える。 index.add("general", "anne").or_die index.add("general", "matthew").or_die index.add("general", "marilla").or_die index.add("sales", "gilbert").or_die # アンが総務から営業に異動する。 index.remove("general", "anne").or_die index.add("sales", "anne").or_die # 部署毎に人員を表示する。 ["general", "sales"].each do |division| puts(division) members = index.get_values(division) members.each do |member| puts(" -- " + member) end end # イテレータでインデックスの全ての内容を表示する。 iter = index.make_iterator iter.first loop do record = iter.get break if not record puts(record[0] + ": " + record[1]) iter.next end iter.destruct # イテレータブロックを使ったイテレーション。 index.each do |key, value| puts(key + ": " + value) end # インデックスを閉じる。 index.close.or_die
最後はGo。やはりC言語っぽい。こんな短いコードでもカーニハン的なスパルタンさが漂ってて良き。API文書はこちら。
package main import ( "fmt" "github.com/estraier/tkrzw-go" ) func main() { // インデックスを開き、自動的に閉じるようにする。 index := tkrzw.NewIndex() index.Open("casket.tkt", true, tkrzw.ParseParams("truncate=true,num_buckets=100")).OrDie() defer func() { index.Close().OrDie() }() // 部署と名前(主キー)のインデックスにレコードを加える。 index.Add("general", "anne").OrDie() index.Add("general", "matthew").OrDie() index.Add("general", "marilla").OrDie() index.Add("sales", "gilbert").OrDie() // アンが総務から営業に異動する。 index.Remove("general", "anne").OrDie() index.Add("sales", "anne").OrDie() // 部署毎に人員を表示する。 divisions := [] string{"general", "sales"} for _, division := range divisions { fmt.Printf("%s\n", division) members := index.GetValuesStr(division, 0) for _, member := range members { fmt.Printf(" -- %s\n", member) } } // イテレータでインデックスの全ての内容を表示する。 iter := index.MakeIterator() defer iter.Destruct() iter.First() for { key, value, ok := iter.GetStr() if !ok { break } fmt.Printf("%s: %s\n", key, value) iter.Next() } }
なお、各言語で、openメソッドにおいてファイル名を空文字列にすると、オンメモリのインデックスが作れる。起動時にメインデータベース全体を走査してセカンダリインデックスを作るなら、ファイルに保存する必要はない。そんなの電力の無駄だろと思うかもしれないが、昨今の計算機なら100万レコードくらいなら秒に満たないで構築できるので、場合によっては全然行ける。オンメモリなんだったらそもそも普通の配列やらリストやらに入れてソートするか、C++のstd::multimapやJavaのMultiMapのようなコンテナに入れても良いのだが、内部でシリアライズしてデータを保持するDBMにデータを任せた方がメモリ使用量が格段に少なくて済む。
各言語において、openメソッドでは、key_comparatorパラメータを与えることで比較関数が指定できる。検索キーを整数値とみなすPairDecimalKeyComparatorを指定すると数値の昇順でレコードを取り出せたり、実数を扱うPairRealNumberKeyComparatorも使えたり、大文字と小文字を無視するPairLexicalCaseKeyComparatorが使えたりする。ランキング的な処理をしたい場合は数値の比較関数が便利だろう。
検索キーを数値として扱うRubyコードの例を以下に示す。インデックスはオンメモリにしてみる。給与やハイスコアみたいな整数データはそのまま検索キーにすると、PairDecimalKeyComparatorがよしなに扱ってくれる。日付はUNIX時間に変換して数値比較で扱ってもいいし、ISO 8601形式(例:2024-04-29T08:30:40+0900)に変換して文字列比較で扱ってもいいだろう。
require 'tkrzw' # 社員データベースのダミー実装。 people_db = { 123 => ["田中一郎", "営業", 254000], 124 => ["大戸島さんご", "営業", 281000], 125 => ["堀川椎子", "総務", 327000], 126 => ["鳥坂司", "総務", 152000], } # 給与インデックスの構築。 index = Tkrzw::Index.new index.open("", true, key_comparator: "DecimalKeyComparator") people_db.each do |id, properties| _, _, salary = properties index.add(salary, id) end # 給与が高い順に社員の全情報を表示。 iter = index.make_iterator iter.last loop do record = iter.get break if not record id = record[1].to_i name, division, salary = people_db[id] printf("給与=%d, ID=%d, 名前=%s, 部署=%s\n", salary.to_i, id, name, division) iter.previous end iter.destruct # 給与が20万円台の社員IDを表示 iter = index.make_iterator iter.jump(200000, "") loop do record = iter.get break if not record or record[0].to_i >= 300000 puts(record[1]) iter.next end iter.destruct # 給与インデックスの破棄。 index.close()
インデックスを分けることで、個別の検索キーに対する比較関数を使った完全一致や範囲検索で対象を絞り込むことができ、効率的な処理が行える。インデックスにおいて、値がユニークであることは要求されるが、検索キーの部分は重複してもいいし、どんな表現形式でも良い。例えば、大文字と小文字を正規化したり、日付を数値に変換したり、地名を座標に変換したり、後方一致のために文字の順を逆転させたりしても良い。範囲検索が効率的にできない検索条件の場合も、対象の属性のみをインデックスに入れて全探索する方が、メインデータベースを全探索するより早いこともある。
DBMはバイト列すなわち任意のバイナリデータを保存する仕組みなので、文字列型を扱う場合には暗黙のエンコーディングとデコーディングが行われていることには注意されたい。CとC++ではバイト列と文字列の区別がなされず、char*やstringで扱われる。JavaとPythonとGoでは文字列型はuint16やuint32の配列なのだが、DBMに保存する際には暗黙的にUTF-8でエンコードされ、読み出す際には同様にデコードされる。UTF-8以外のデータを保存したい場合、自分でエンコードしたバイト列を渡し、取り出したデータを自分でデコードすればよい。Rubyの文字列型はバイト列にエンコーディングのラベルがついている構造なので、ラベルに関わらずそのまま保存するが、読み出す際にどのラベルをつけるかはopenに渡すencodingパラメータで選べる。
あと、細かいことだが、PythonとRubyとGoでは各メソッドのパラメータとして渡すデータは暗黙的にバイト列に変換してくれる。返却値はその限りではないので、必要に応じてバイト列から文字列や数値に変換するか、PythonやGoではIndex#GetValuesやIndexIterator#GetStrを読んで文字列として取得すると良い。Javaでは引数が文字列のメソッドは文字列を返すが、イテレータのgetは引数を取らないので、バイト列を返す仕様になっている。文字列が欲しいならIndexIterator#getStringを呼ぶと良い。
各言語で同じ処理を実現したコードをこうして並べてみると、この程度の複雑さではどの言語もそんなに変わらないなと思えてくる。さすがにC言語はリソース管理が面倒すぎるが、他の言語はどれも十分に便利なコンテナやその他のユーティリティが揃っているので、どれも使うのに躊躇はない。強いて言えば、小規模なプログラムをちゃちゃっと書くには型が柔軟なPythonやRubyを私は選ぶだろうし、何人かで大規模なプログラムを書くならC++やJavaを選ぶだろうし、並列性が必要なサービスを書くならGoを使うかもって感じかな。まあ大規模なプログラムで敢えてDBMを使うってこともそんなにないだろうけど。
余談だが、国民情報のデータベースを運用するにあたって、マイナンバーという名の主キーを設定したいというのは至極当然のことなので、反対している人達は主張方法を考え直してほしい。データベース化されること自体を嫌悪しているのだと思うが、それだったらマイナンバーが導入される前から戸籍やら土地登記やら税金やら年金やらで各所にデータベースが存在しているわけで、個々の存在を調べて個別に妥当性を検証すべきだろう。マイナンバーを攻撃するのは本質から目を背けさせるだけだ。仮にいくつかは妥当なデータベースだったとすると、各レコードの主キーが内部的に別々で、相互参照の際に氏名やら住所やら本籍地やらの、ユニーク性や永続性が全く保証されていないものを使っている現状の方が恐ろしい。「同姓同名の人がいたので住民税の請求先を間違えた」みたいなニュースがたまにあるが、氏名で請求先を特定せにゃならん役所の人の心労を慮るばかりだ。各所のデータベース管理システムの運用が杜撰なのはまた別の話だが、それもマイナンバーのせいではない。
まとめ。Tkrzwの各言語のインターフェイスにて、セカンダリインデックスの機能をサポートした。こいつを使うと、データベースであることをほとんど意識せずに、永続化した大規模のデータを扱うプログラムか書ける。